

Updated twice, on June 13th and June 22nd – see the updates at the bottom.
Like many others, I misread what Anthropic did with their new model Mythos – now officially Mythos 5 – over the past few months, when they didn't release it to the public but only to Project Glasswing partners. I assumed it was a marketing stunt: the model would surely be better than the previous ones, but the whole story around it felt exaggerated. Their argument about implementing safeguards and guardrails first – so users cannot abuse the model for malicious exploits against other entities – sounded like an excuse to me. The real reason, I thought, was that they simply didn't have enough compute available, because the new model needs many more tokens and a huge amount of compute.
I was wrong.
The safeguards were not an excuse: through Project Glasswing, around 200 vetted organizations across more than 15 countries have been scanning critical codebases – power, water, healthcare, communications – with the Claude Mythos Preview and have found more than 10,000 high- or critical-severity security flaws. And compute was not the real bottleneck either. The public version simply needed new safety classifiers first – for cybersecurity, biology and chemistry, and distillation attempts – which now route affected queries to Opus 4.8 in flagged sessions.
I started this blog series with my AI coding journey, and that journey began in early December – exactly half a year ago, a few weeks after Opus 4.5 was released. That release was clearly an inflection point, at least in my personal history, because with that model I could write – or let's say prompt – code for the first time. I hope this doesn't sound arrogant, but I'm quite opinionated about how code should look, and Opus 4.5 was the first model that wrote code as if I had written it myself: the same quality, the same style, the same patterns, and so on. Until Opus 4.5, I thought these agentic tools just create slop. I was proven wrong six months ago.
Now I thought the Mythos story was a marketing stunt – and again, I was proven wrong. On June 9, 2026, Anthropic released Fable 5 to the public – the same underlying model as Mythos 5, but with the new safeguards in place. And this isn't just another release. This is a new generation of LLMs, and it is really, really capable.
You can use it for everything you previously used GPT 5.5 or Opus 4.8 for – it just does the job even better, with a level of quality and robustness I haven't seen before. I personally have to admit: it writes code better than I would. That is of course not to say I'm obsolete. The model still needs a skilled and senior web developer to steer it in the right direction for a high-quality result. And that is always my goal: to ship high-quality code, no matter what the project or the setup might be.
Honestly, I didn't plan to publish any model updates in this series, at least not in the first three or even six months, because I'm kind of annoyed by all the model hype posts and videos. But as I already said, I think this model really is a new generation, so I had to cover it here. Yesterday, Manfred asked me why I think this model is a new generation, and it was surprisingly hard for me to answer. I said: "Let me think about it. I will tell you tomorrow – or even better: I will write a blog post about it."
So this is the post.
What Makes Fable 5 a New Generation?
The first thing that makes Fable 5 a new generation is the quality of the code it writes. The code is not just good, it's really high quality. It follows best practices, it has good structure, it's clean, and it looks like it was written by a good senior developer. This is a huge step up from previous models. I used it to review work I had previously done with GPT 5.5 and Opus 4.8 – it immediately tracked down bugs, issues, and potential issues. I also used it for simplification, and it handled that just as well. So it can basically be used for everything.
An incomplete list of outstanding features and capabilities of Fable 5 includes:
- Long-horizon autonomy: Anthropic says Fable 5 can stay with a problem far longer than any model before it and operate for days without intervention. Andrej Karpathy called it a step change of the same order as Opus 4.5 was in November – especially for long problem-solving sessions on very difficult problems. I totally agree with him, and that is the actual reason for writing this post. This is the model you point at a problem, not at a file.
- Vague goals in, validated results out: you can hand it an instruction as open as "look into options to make this more performant", and it will synthesize ideas, test them – even write its own fuzzers and test beds – and come back with validated results instead of a guess. Skills and elaborate prompt engineering are not really necessary anymore – although I dare to make a prediction: they will play a huge role again in the future, when token efficiency becomes the highest priority.
- Token efficiency despite the price tag: at roughly €10 per million input and €50 per million output tokens (official pricing is in US dollars; converted to euros and rounded up a bit), it costs about double Opus 4.8 per token. But it needs far fewer tokens per task, so on DeepSWE – still my favorite coding benchmark – the early numbers put it roughly on par with GPT 5.5 while beating every Opus score at lower total cost. Artificial Analysis has already run the new model through their coding-agent version of DeepSWE (see the chart below), and the official DeepSWE leaderboard now shows the same story from the benchmark source itself.
- Benchmark jump: on the Artificial Analysis intelligence index it is now simply the smartest model ever measured, about five points ahead of GPT 5.5 – one of the biggest single jumps in a long time. As always: useful signals, not final answers.
- Vision: for the first time, Anthropic takes the vision lead from OpenAI. That matters more than it sounds for our work – think screenshot-based UI verification of Angular components and design work with real taste instead of the same old templates.
- Not just coding: Anthropic explicitly positions it for finance, research, economics, and law – and the early reviews agree that even its writing is noticeably less LLM slop than before.
To that last bullet, I would personally add design and writing – basically anything from emails to project planning. It is incredibly good at all of these things. It does what you tell it to do, it guides you through the process of whatever you are working on, and it comes back with useful proposals for the next step towards your goal.
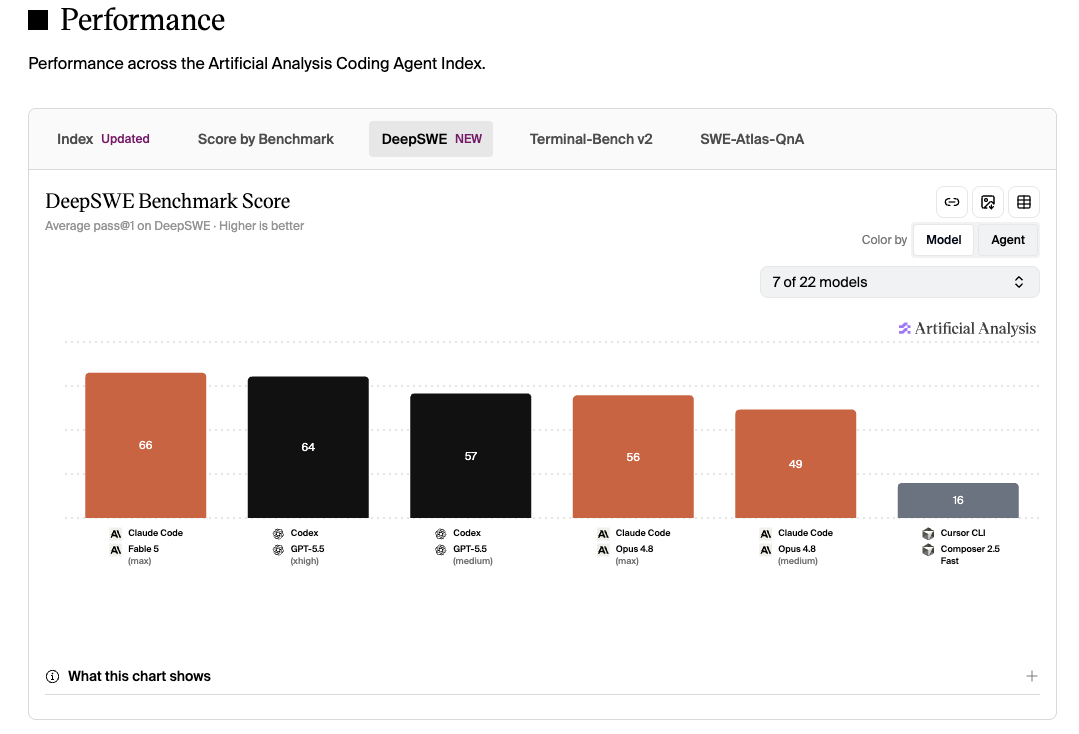
DeepSWE scores for the current coding agents, captured on June 12, 2026 – click the chart for the live comparison. Strictly speaking, these are coding-agent results, so the harness matters: Fable 5 runs inside Claude Code at max effort here. The nice bonus of this view is that it even includes Composer 2.5, which the original DeepSWE leaderboard could not test due to the missing public API.
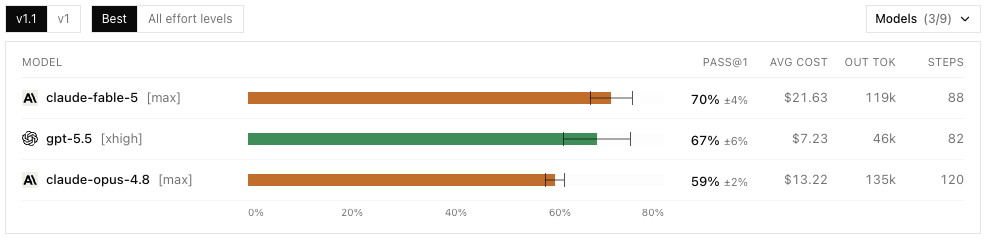
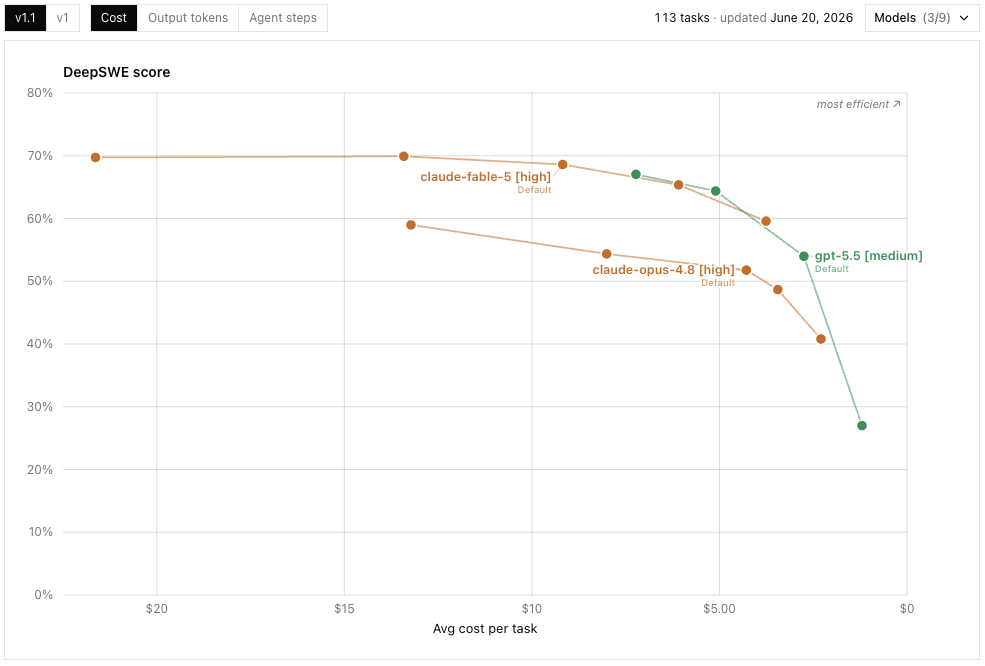
The official DeepSWE leaderboard, updated June 20, 2026, now puts Fable 5 at 70% pass@1 on v1.1, narrowly ahead of GPT 5.5 at 67% and clearly ahead of Opus 4.8 at 59%. The cost view is the important caveat: Fable 5 is the strongest model in this slice, but not the cheapest one, so I would use it for hard, long-horizon engineering work where the extra quality actually changes the outcome.
So this model really is insanely good – almost too good to be true. Which brings us to the obvious question: what's the catch?
Every Fable Has Its Fine Print
There is not one catch, there are several – some are merely annoying, some might be deal-breakers for your setup.
The safeguards are real, and you will notice them. Anthropic says fewer than 5% of sessions get routed to Opus 4.8, and in my coding work so far that matches – I have not hit a single refusal yet. But Artificial Analysis recorded fallback routing in 8% of their benchmark tasks, mostly on scientific questions. At least the routing is transparent: when it happens, you are told.
One safeguard is silent, though. When Fable 5 detects that you are working on frontier LLM development, it does not notify you – it quietly limits its own capabilities through prompt modification, steering vectors, and parameter-efficient fine-tuning. Anthropic estimates this affects 0.03% of traffic and fewer than 0.1% of organizations, so most Angular developers will never encounter it. Still, paying full price for a quietly limited model is a precedent I really don't like.
There is no zero data retention. All Fable 5 traffic requires 30-day retention – even for enterprise customers, with no opt-out. Anthropic claims the data is not used for training or any non-safety purposes, but as I wrote in the data privacy post: "not used for training" does not mean "not retained". For regulated industries and strict company policies, this alone can be a non-starter.
And now to the three catches that affect all of us directly:
The clock was ticking – faster than expected. Fable 5 was effectively available to me only from June 10 through June 12, 2026. Originally, I wrote that the included window would close on June 22 and then require usage credits. That turned out to be far too optimistic: on June 12, Anthropic had to disable Fable 5 and Mythos 5 for all customers after a US government directive. For roughly three days, we saw the next generation, and then it was gone.
It is slow. Even simple tasks take one to three minutes, and I have barely seen a run finish faster. This is not a model for the tight interactive loop where Composer 2.5 or GPT 5.5 on low reasoning shine. But as I argued in the costs post, the practical speed metric is not tokens per second – it is the end-to-end time until I have a reviewed diff. For long autonomous runs, Fable 5's pace is acceptable. For quick edits, use something else.
It is expensive. Roughly €10 input and €50 output per million tokens is about double the Opus 4.8 price, and the usage limits drain accordingly: early adopters report burning through roughly €100 of usage-based inference in less than ten minutes, and maxing out the 5-hour session limits of two €200 subscriptions in a single evening. Yes, it needs fewer tokens per task, so the cost per accepted, reviewed, merged change can still come out ahead for hard problems. But for everyday edits, this model is simply overkill – and after June 12, it was not priced like anything anymore because it was gone.
So my original call to action aged badly: we did not have until June 22. We had June 10 to June 12, and then the model was shut down. If you tested it in that tiny window, you got a glimpse of what a next-gen model can do for a real codebase. If not, we are all waiting to see whether Anthropic can bring it back.
My Updated Current Setup
In my personal verdict, published less than two weeks ago (in early June 2026), my default was Codex with GPT 5.5, complemented by the Claude Desktop app with Opus 4.8 for architecture, design, refactoring, and reviews. Three days of Fable 5 have turned that ratio upside down:
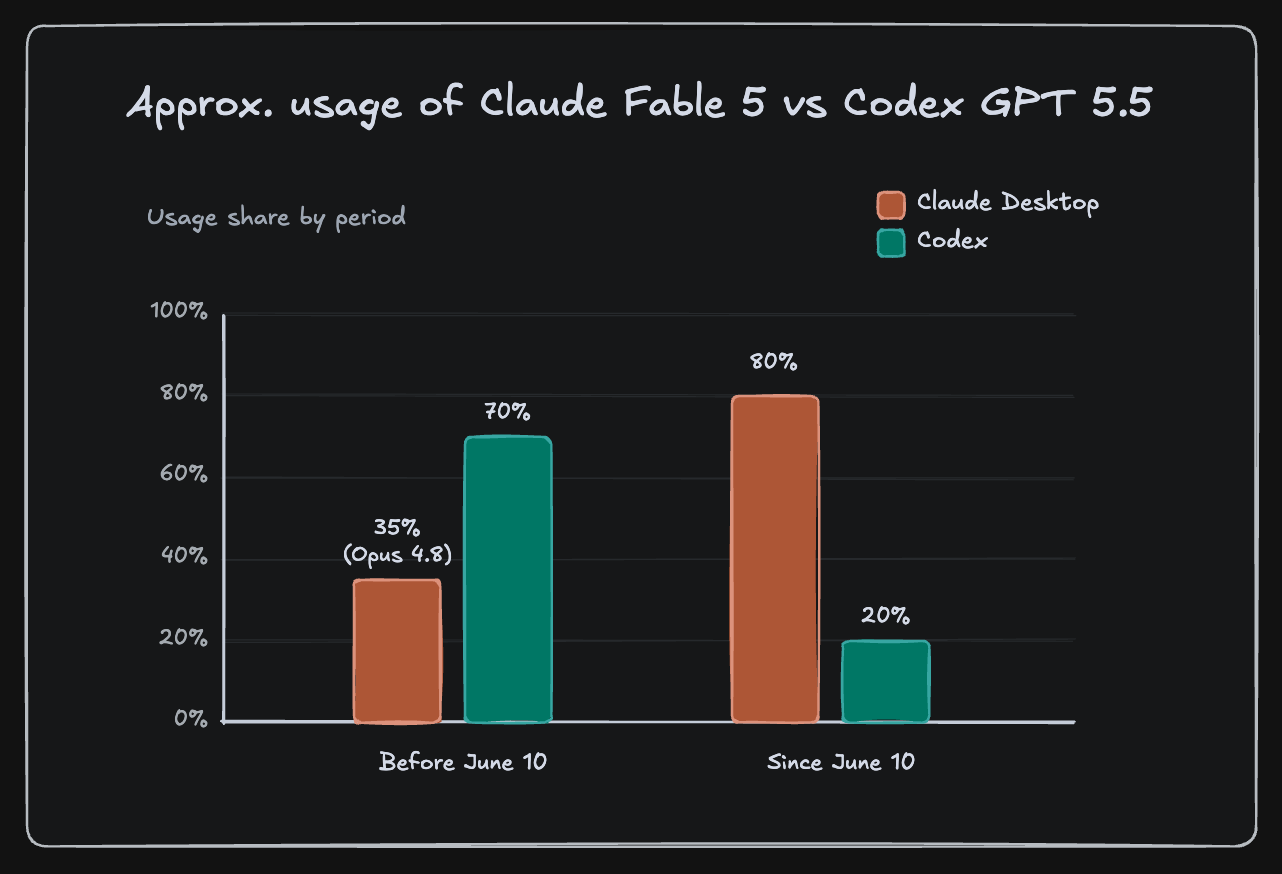
- Before June 10: Codex with GPT 5.5 was my default (70%), while the Claude Desktop app with Opus 4.8 handled architecture, design, refactoring, and reviews (35%).
- From June 10 to June 12: the Claude Desktop app with Fable 5 took 80% of my work, Codex with GPT 5.5 the remaining 20%.
Attentive readers of that verdict will remember why my old percentages added up to more than 100%: I used to review what each of the two main apps produced with the other challenger. That habit has basically stopped now – there is simply no need to review Fable 5's work with GPT 5.5, because Fable 5 is just way better.
I do keep using Codex for computer use, image generation, and simple tasks that should be done very fast – exactly the kind of work where Fable 5 would be wasted. And I'm not planning to cancel my OpenAI subscription either, because I guess we will soon see GPT 6 as the response to Fable.
So the decision tree from the personal verdict still stands – but its top branch has a new label, at least for now.
Human in the Loop – for How Much Longer?
There are basically two camps in the agentic engineering field right now.
The first camp is the progressive one. Their position: "Just trust the coding model. You don't have to review its work anymore – human review is the new bottleneck." A lot of my friends sit in this camp.
The second camp says: "You still need to review everything the model builds, because that is the only way to keep slop out of your codebase." If you have read this series, you know which camp I belong to: in the apps and harnesses post, I wrote that I review every diff and expect every generated line to look as if I had handcrafted it myself, and the later harness setup post turns that idea into concrete guardrails. A lot of my colleagues sit in this camp. Some of them are still trying to find time to even try agentic engineering. Crazy, right?
I was fully convinced of the human-in-the-loop (HITL) position. The last two days have made me a lot less convinced.
Not because my standards dropped, but because the reviews changed sides: as described above, I let Fable 5 review work that GPT 5.5, Opus 4.8, and I had produced together – and it found the bugs, the issues, and the simplifications, not me. When the model reviews my work more reliably than I review its work, the question is no longer whether human review is sacred. The question is what it still catches.
So here is the uncomfortable sentence I did not expect to write this soon: I can imagine that human reviews really become obsolete in the near future – not because we get lazy, but because they stop finding anything the model has not already found itself.
For now, I have not changed my workflow: every diff still gets my review, and that is also what I still recommend to every professional Angular team. But for the first time, this feels less like a timeless principle and more like a practice with an expiry date. Ask me again in six months. Or even three. Let's see. Exciting times!
Agentic Engineering Workshop
And this is exactly why a new model – even a new generation – does not change the fundamentals: the model, the app, my Angular Guardrails, my Angular Coding Style Guide, and the review workflow still belong together. Fable 5 just raised the ceiling of what that system can do.
If you want to judge new models like Fable 5 on your own codebase – and put them to work on real modernization, refactoring, testing, and review tasks – join our Agentic Engineering Workshop, available in English and German. In it, advanced Angular developers learn how to move from vibe coding to traceable Agentic Engineering workflows: AI-ready project setup, guardrails, spec-first and plan-first workflows, UX and component prototyping, code review, testing, and brownfield refactoring.
- 🤖 Agentic Engineering Workshop – 2 days, remote
Conclusion
Half a year ago, Opus 4.5 convinced me that agentic tools can write real code. Fable 5 is the first model since then that gives me the same feeling of crossing a threshold – not because of benchmark wins, but because of what it does in my own daily work: it stays with a problem, it validates its own results, and it writes code I like and want to merge.
In the first post of this series, I wrote that benchmark wins are useful signals, not final answers, and that no single release should change your workflow overnight. I stand by that – and yet Fable 5 is the first release that made me update my setup within days, and the first that made me question my own human-in-the-loop dogma. Both things can be true: stay skeptical of the hype, and recognize a new generation when it lands in your terminal.
The catches are real: the safeguards, the data retention, the speed, the price, and above all the June 12 shutdown. So let me correct my original call to action one last time: the included Fable 5 window did not close on June 22; it ended on June 12, 2026, when Anthropic disabled access after the US government directive. If it comes back, judge it the same way I recommended for every model before it – in your own codebase, with your own tasks, your own tools, and your own review standards.
One last confession: this is my first model-release hype post – exactly the kind I claimed to be annoyed by at the top. I hope I don't have to write another one anytime soon. Wait, there will probably be one when GPT 6 lands – let's see how long it takes OpenAI to respond.
Thank you for reading 🙏 this blog post was written by Alexander Thalhammer. For feedback, remarks or questions, please reach out to me ❤️
Update June 13th
So this is the real catch: The model was shut down by the US government. Really sad. What a shame. So the AI war has escalated – let's see what happens next. For now, we're back to doing more of the work ourselves.
Update June 22nd
Inserted new charts by DeepSWE from June 20th. Still waiting for the model to be released again.