

My AI Coding Journey
It's almost six months since my last post on this blog, published in early December 2025. In that time, my daily work changed rapidly and completely. Until November 2025, I thought AI was not useful for my work in complex enterprise Angular projects, where code quality has to be very high.
But then Opus 4.5 was released to the public on November 24, 2025. I started to experiment with it and quickly found that it could help with real work: code generation, code review, documentation, modernization, refactoring, and a lot more.
The quality surprised me first. Some generated Angular code looked close to how I would have written it myself. The speed surprised me next. Naturally, I felt a bit obsolete, but it was and still is pretty exciting.
The biggest change is not that the latest models write better code. The bigger shift is that using them has become much easier: I no longer need to craft a perfect prompt upfront and hope that the result matches my intent. Instead, the interaction feels much closer to talking to a senior developer: I can describe the problem, add constraints, answer questions, clarify the spec, and let the model help discover what we actually want to build.
If you've been working with AI every day for months, there might not be much new for you in this post. But if you are rather new to Agentic Engineering and want to understand which LLM is best for Angular development, this post is for you.
Comparison from November 2025 (Outdated!)
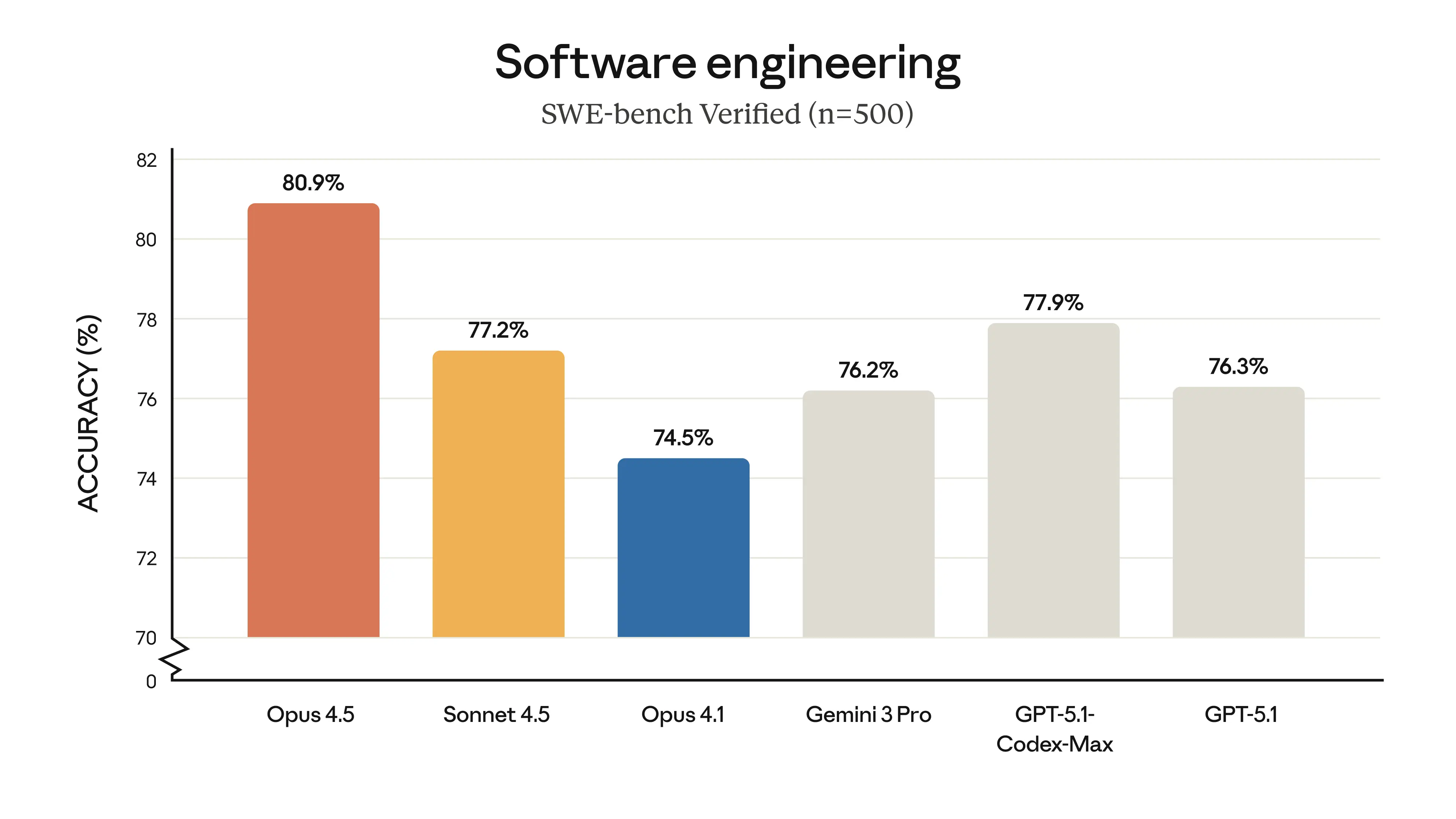
BTW: SWE-bench itself is also showing its age. I will use more recent coding-agent benchmarks from Artificial Analysis later in this post.
I started using Opus 4.5 through my favorite IDE, WebStorm. But in this post, I don't want to talk about IDE integration, harnesses, and tools yet. That part of the journey deserves its own post. Here, I want to stay focused on one question: which LLM is the best fit for Angular development?
There is no public Angular benchmark, so we have to combine two imperfect sources: existing public coding benchmarks and personal experience from real Angular work. I want to start with the public benchmarks and then move to my own verdict.
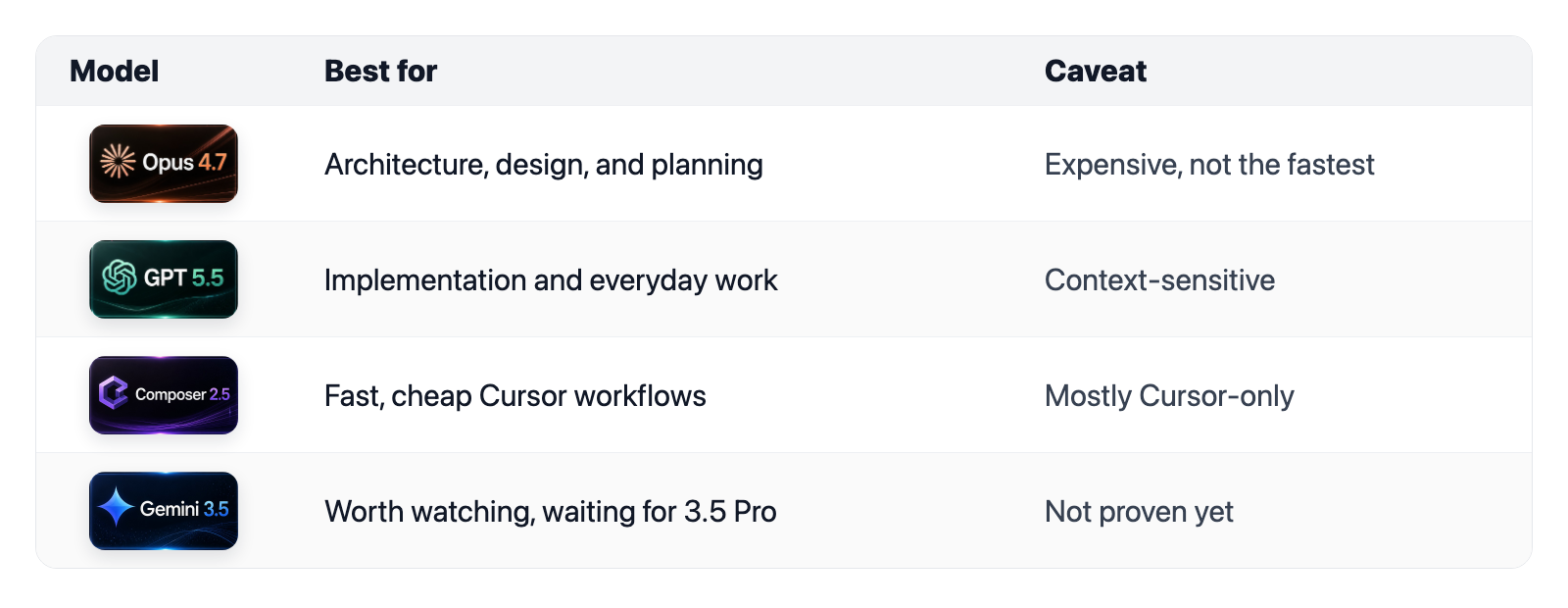
TL;DR: My Current Ranking
In short: Opus 4.7 is my #1 for Angular, GPT 5.5 my #1 all-rounder, Composer 2.5 the newcomer to watch, and Gemini 3.5 Flash still experimental for now. The table below has the details:
Which Frontier LLMs Are Relevant for Angular in May 2026?
I personally want to use the best and latest LLMs that I can realistically use for Angular development, so I will mostly talk about frontier models that are generally available through common developer tools, APIs, or IDE integrations.
In my subjective opinion, the most relevant frontier LLMs for Angular development currently are (sorted by release date – earliest to latest):
- Opus 4.7 by Anthropic, April 16, 2026
- GPT 5.5 by OpenAI, April 23, 2026
- Composer 2.5 by Cursor, May 18, 2026
- Gemini 3.5 Flash by Google, May 19, 2026
The last two were released to the public only a few days before I wrote this, so I have not had the chance to experiment with them a lot yet. Still, I think Opus 4.7, GPT 5.5, and Composer 2.5 are the current candidates for the best LLM for Angular development. Gemini 3.5 Flash is included here because it is new and interesting, but my first impression is that it is not really a challenger to the other three models in this post. I'm still pretty sure Gemini 3.5 Pro will be a serious contender once it is released.
Public Benchmarks
At Google I/O in May 2026, Google released a bunch of new AI updates. One of those releases was Google Gemini 3.5 Flash, and the release notes included some benchmarks:
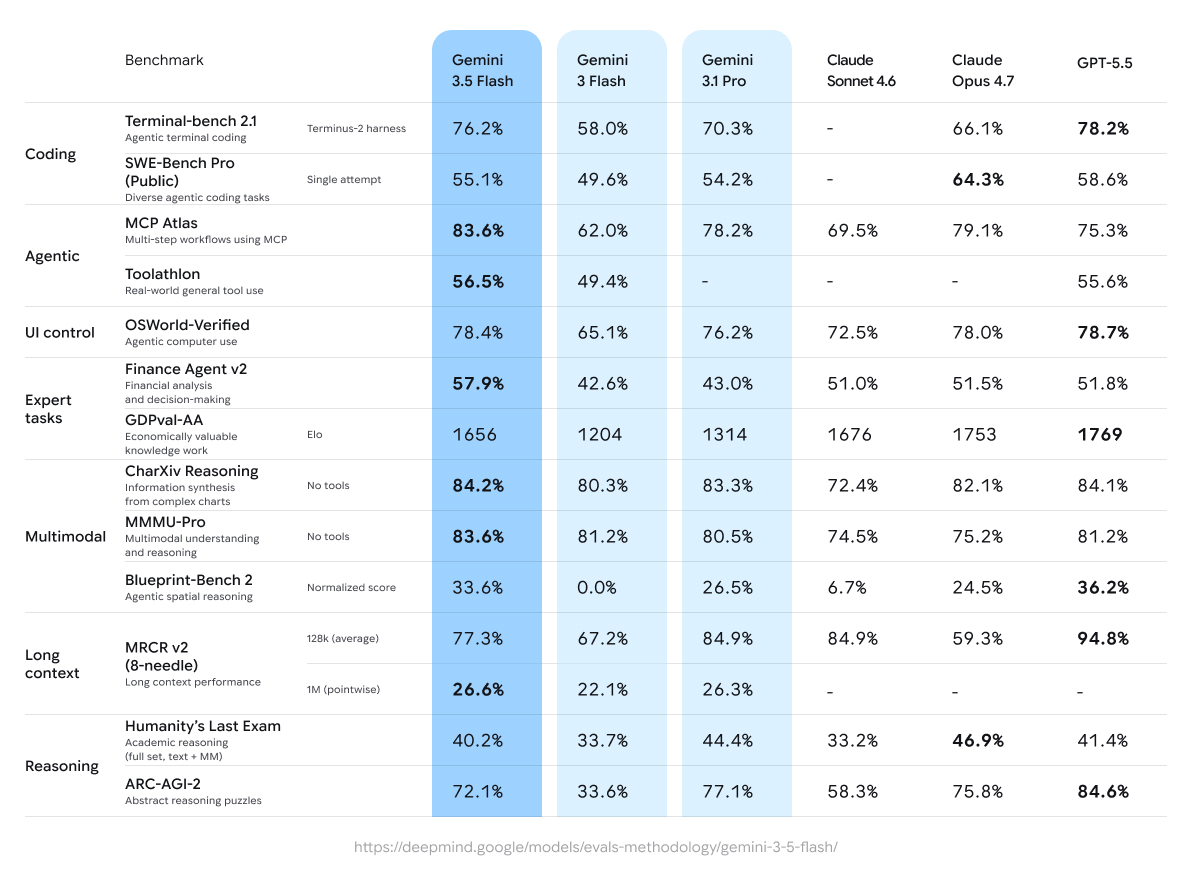
I see at least two problems here:
- This is vendor-provided marketing material for Gemini 3.5 Flash, so it is not really objective.
- We don't know enough about what the benchmarks are, how they were conducted, and what the results really mean for Angular development.
So what can we use instead? My favorite benchmarks are done by Artificial Analysis. They are still not Angular-specific, but they give us a better baseline for comparing model capability, speed, and token usage.
Artificial Analysis Benchmarks
I want to show you three views from Artificial Analysis: the "Coding Agent Index" for overall coding-agent performance, "Execution Time" for active agent runtime, and "Token Usage" for how much context and output the models need to solve tasks. The screenshots below were captured on May 26, 2026, so check the live leaderboard for the latest numbers.
Strictly speaking, these are coding-agent benchmarks, not pure LLM benchmarks. The harness matters a lot: the same model can behave differently in Claude Code, Cursor, Codex, OpenCode, an IDE integration, or a custom agent setup. That is why I cover harnesses and integrations separately in the apps/harnesses post and the practical setup side in the harness setup post; here I only use these numbers as a rough signal for model quality.
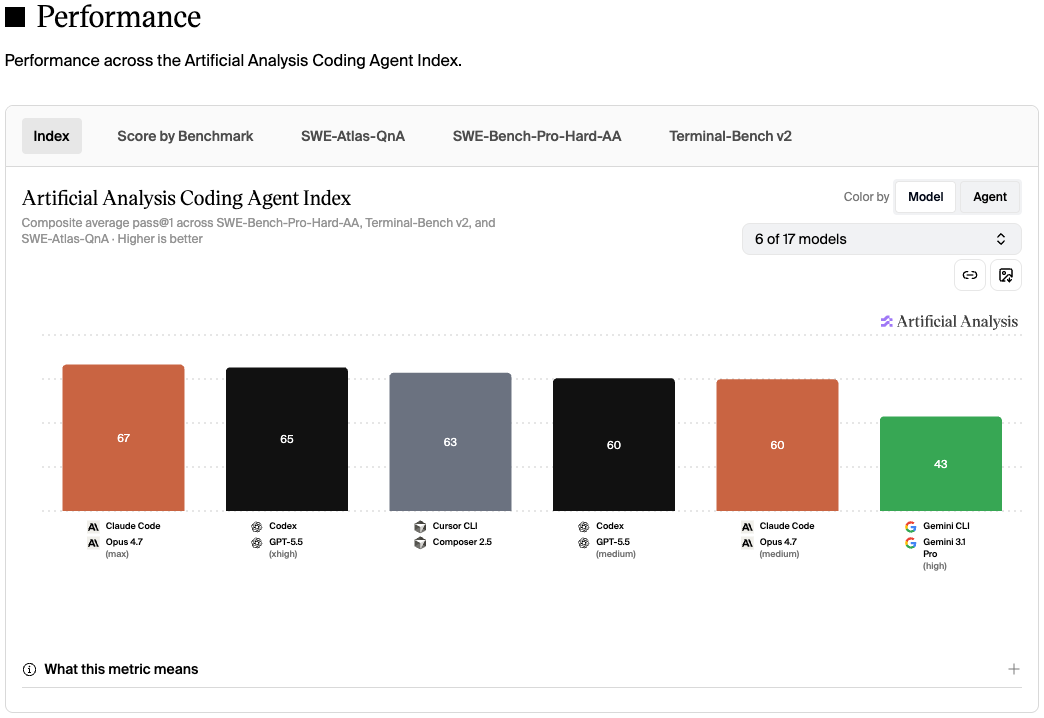
The Artificial Analysis Coding Agent Index is a composite score built from SWE-Bench-Pro-Hard-AA, Terminal-Bench v2, and SWE-Atlas-QnA. You can read their coding-agent benchmark methodology for the details.
It is useful for quick comparison, but it should be read alongside the per-eval breakdowns. Two agents with similar index values can still have different strengths across repository tasks, terminal workflows, and rubric-based evaluations.
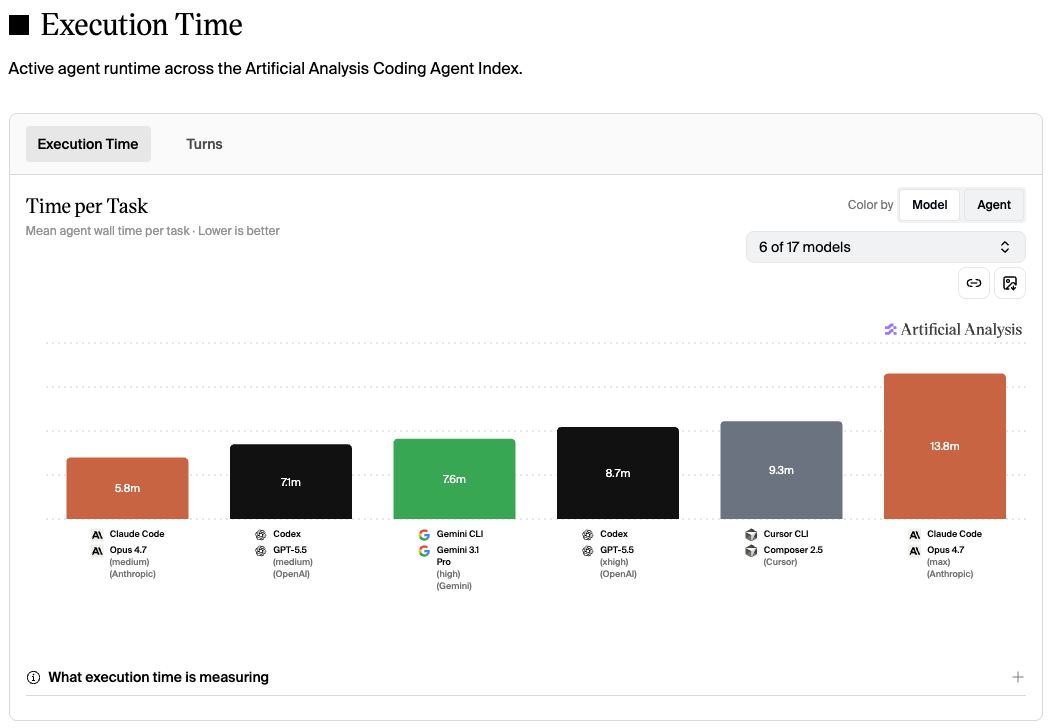
Mean agent wall time per task. Lower is better.
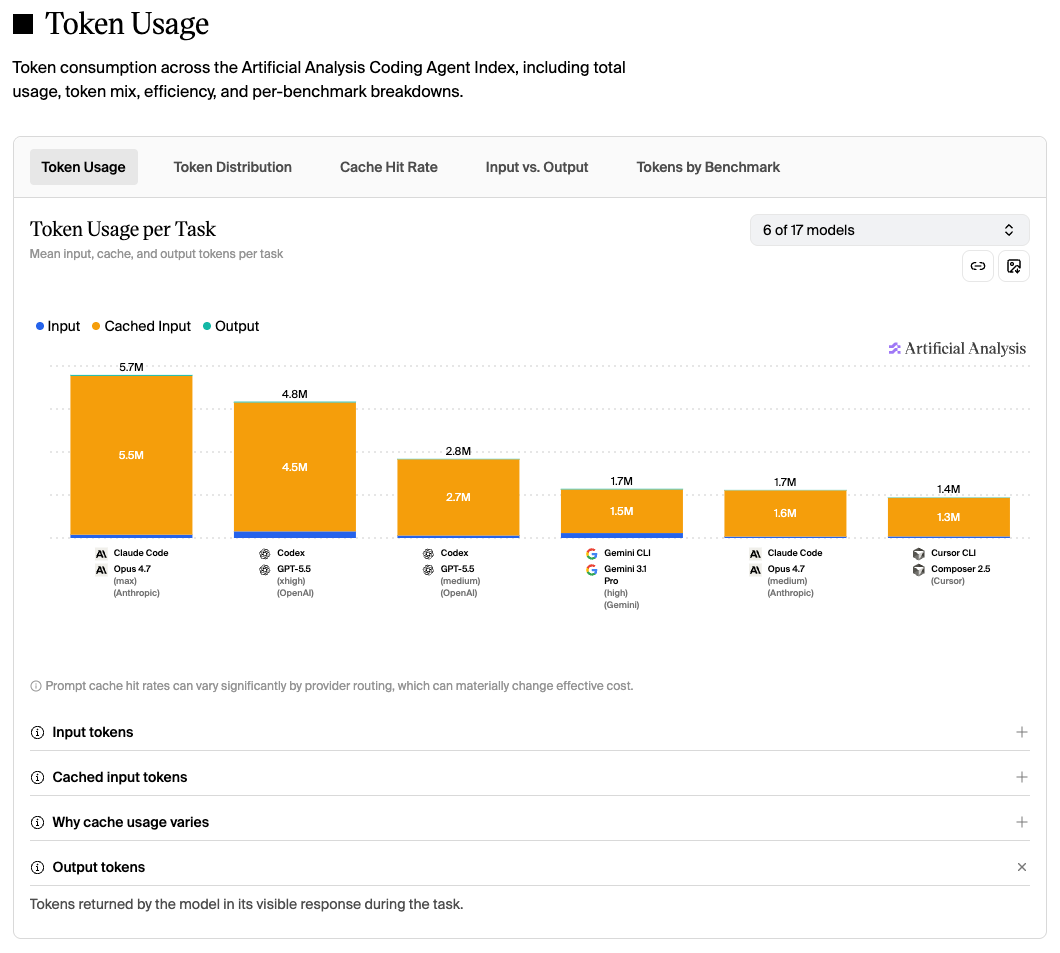
Mean input, cache, and output tokens per task.
DeepSWE Benchmark
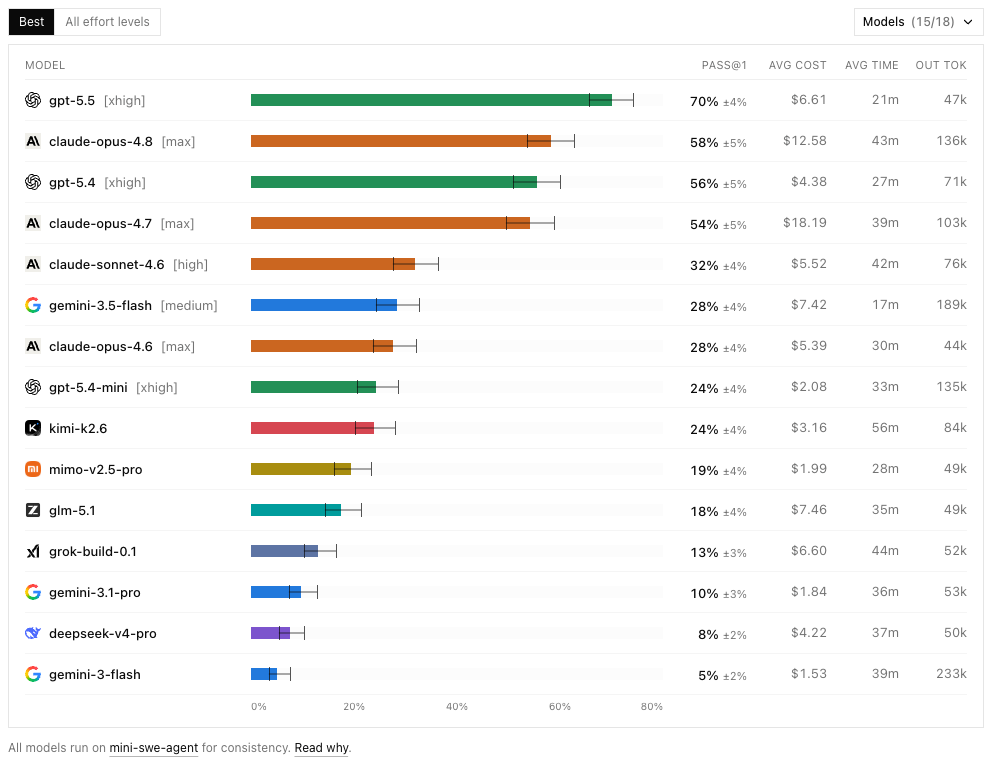
Update May 31st (including Opus 4.8): Another recent benchmark that matches my day-to-day impression more closely is DeepSWE. In this leaderboard – a snapshot from May 31, 2026 – GPT 5.5 leads at 70%, followed by Opus 4.8 at 58%, GPT 5.4 at 56%, Opus 4.7 at 54%, and both Opus 4.6 and Gemini 3.5 Flash at 28%. DeepSWE has since moved on to v1.1 with updated numbers, so treat these as the May snapshot and check the live leaderboard for the latest state. That lines up with my current feeling: GPT 5.5 and Opus 4.8 are both strong for serious coding work, while Gemini 3.5 Flash still feels more experimental for Angular development.
What I like about this benchmark is that it focuses more on the kind of work that matters in real agentic workflows: can the agent take a short behavioral prompt, find the right area of the codebase, and implement the change cleanly without me spelling out every file, module, and function? That is exactly the kind of workflow where traditional SWE-Bench results can feel disconnected from daily coding experience.
The most interesting part is not only the ranking itself, but the size of the gaps. A benchmark that makes a smaller model look almost as capable as a frontier coding model is not very useful for my daily work. DeepSWE feels more realistic because those gaps open up again: the weaker models fall back to where I would expect them from real agentic coding, while GPT 5.5 and Opus stay clearly ahead.
Composer 2.5 is unfortunately not part of this comparison, probably because it is mostly available through Cursor surfaces and not as a normal standalone model API.
What the Benchmarks Suggest
In these benchmark results, Gemini 3.1 Pro – still the current Pro tier, since Gemini 3.5 Pro has not shipped yet – does not look competitive with the other models. Gemini 3.5 Flash looks more interesting, but the public data is still very fresh and not specific to our framework.
My personal Angular impression is similar, but not identical: Gemini 3.5 Flash is sometimes fast and sometimes not, and it does not yet feel like a real challenger to my top three for my work. Gemini 3.5 Pro might become the more serious candidate here, but we don't have enough data yet.
In this benchmark snapshot, GPT 5.5 wins overall and is more efficient. So let me be upfront about the tension: the benchmarks I trust most currently lean GPT 5.5, yet my own Angular verdict below still puts Opus on top. That gap between leaderboard and lived experience is exactly why I treat these numbers as signals to weigh, not answers to follow.
I don't want to look at cost in detail here. That deserves its own follow-up after the tools and harnesses post, because cost depends heavily on how you access these models. For this post, the central question is still the same: which model gives Angular developers the best mix of quality, speed, and practical usefulness?
I also don't want to pretend that this post is a real benchmark. The deeper Angular evidence behind my preferences comes from my own daily work experience with modernization tasks, refactorings, code reviews, testing workflows, and brownfield scenarios. In our Agentic Engineering Workshop, I will show practical examples of why these models became my current favorites for professional Angular work.
Before I move to my personal verdict, there are four side questions worth clearing up because they often come up when comparing current LLMs: Chinese models, European models, local models, and whether any of them are actually open source.
But what about the Chinese LLMs?
As of May 2026, Chinese LLMs like DeepSeek V4, Qwen 3.6, and Kimi K2.6 are absolutely worth watching, especially because they are pushing very hard on coding quality, open weights, and low cost. But for serious Angular development, I have not seen enough evidence yet to put them in the same tier as Opus 4.7, GPT 5.5, or Composer 2.5, so for now they are interesting to observe, not models I would bet my enterprise work on.
And what about the European LLMs?
As of May 2026, European LLMs are mostly a Mistral story for me, with Mistral Large 3 as the latest model worth tracking: interesting, improving, and relevant when data residency, EU vendors, or open-weight deployment matter. But for raw coding capability in my Angular work, I would not rank them with the frontier labs right now, so I would treat them as strategic options rather than serious candidates for the best model.
And what about local LLMs?
As of May 2026, local LLMs are no longer just toys, but we have to be precise about what "local" means. Running a model on my MacBook Pro is very different from self-hosting a huge open-weight MoE (Mixture of Experts) model on serious GPU infrastructure.
For local or self-hosted coding workflows, Qwen 3.6 is probably the most interesting family to watch right now, especially because the Qwen team explicitly focuses on agentic coding, repository-level reasoning, and local deployment via Transformers, llama.cpp, MLX, vLLM, and SGLang. DeepSeek V4 is also very relevant in the open-weight space, but the larger variants are more realistic for server-side self-hosting than for a normal developer machine. From Europe, Mistral 3 is interesting because Mistral Large 3 and the smaller Ministral 3 models are open-weight, with the smaller models explicitly targeting edge and local use cases.
For my professional Angular work, I would not put local models in the same tier as my current favorites yet. The gap is not only raw model quality, but also tool use, long-running agent reliability, context handling, and integration quality. Still, local models are becoming useful for privacy- or regulatory-sensitive work, CI helpers, and teams that want more control over where their code goes. I would not ignore them anymore, but I also would not make them my choice for enterprise Angular development today.
Are any of these models open source?
This is where the wording gets a bit tricky, because with LLMs people often say "open source" when they really mean "open weights". Claude, GPT, Gemini, and Composer 2.5 are not open source models in the practical sense, although Composer is based on Moonshot's open Kimi checkpoint. DeepSeek, Qwen, Kimi, and some Mistral models are much closer to that world because their weights are available under permissive or semi-permissive licenses. Still, even there, we usually don't get the full training data, training code, and recipe, so I would call them open-weight models rather than fully open source models.
My Subjective Verdict
With that context out of the way, I want to move to my own experience with these LLMs. For me, the real question is not only which model wins a benchmark, but which model fits which part of an Angular workflow. This part is purely subjective, and I'm open to other opinions and experiences. If you disagree with me, please let me know in the comments on X or Reddit.
My #1 for Angular: Opus 4.7 by Anthropic
My favorite model is Opus 4.7. It is the best LLM for Angular development in my opinion because it has the strongest code quality, the best overall performance, and still feels fast enough for serious agentic work.

It is also the most versatile LLM. The big shift for me is that Opus 4.7 no longer feels like a junior helper that needs tiny step-by-step prompts, but more like a senior partner that works best when I give it context, constraints, and good questions.
I think this model is currently the most capable one for complex enterprise Angular applications. It's also the most expensive one, especially in Extra and Max Mode, but I think it's worth it for the quality of the results.
I really like doing agentic work with this model, especially for tasks where I want it to explore trade-offs, challenge assumptions, and come back with a concrete implementation plan. In the follow-up post about tools and harnesses, I show how I use it in practice.
My #1 all-rounder: GPT 5.5 by OpenAI
GPT 5.5 is also a great LLM for Angular development, and OpenAI's introduction matches what I see in practice: its real strength is focused implementation work. It writes excellent code and is very token-efficient, especially when you do not force the highest reasoning level. However, it is not as versatile as Opus 4.7, and I find it more sensitive to context: if it starts from the wrong assumption, I often get better results by opening a fresh thread with clearer constraints instead of trying to steer the old one back.

That efficiency matters because GPT 5.5 is expensive per token, but it often needs fewer tokens to finish a task than competing frontier models. For practical work, I would start with lower or medium reasoning and only move up when the task really needs it.
For everyday chat use cases, I really like this model. I use it for a variety of tasks, especially when I want to think through a problem by asking a series of focused questions, then start a clean implementation thread once the direction is clear. For example, if I need help fixing the language of this blog post, I will definitely choose GPT 5.5, but I also (currently) prefer it for modernization and refactoring of Angular projects. Have you tried resolving hard merge conflicts? Oh boy, that's really a relief. Hard to trust though because it's so fast. I think it's kind of a senior engineer while Opus 4.7 is the better architect, but that's for sure subjective.
My #1 newcomer: Composer 2.5 by Cursor
Composer 2.5 is a very interesting LLM for Angular development because it combines good code quality with very high speed. The most interesting claim from the current discussion around it is that Cursor post-trained it on Moonshot's Kimi K2.5 open-weight checkpoint and, on Cursor's own benchmark, got surprisingly close to GPT 5.5 and Opus 4.7 at a much lower cost. The important caveat is that this is still hard to verify independently because Composer is mostly available through Cursor surfaces, not as a normal model API.

If costs are important to you and you cannot rely on generous included usage in paid plans such as Claude Code or Codex, Composer 2.5 might be the best option for your setup, but only if Cursor fits your workflow. I cover tools and harnesses in the follow-up post, and then come back to costs and access models in a dedicated follow-up.
Candidate to watch: Gemini 3.5 Flash now, Gemini 3.5 Pro later

Gemini 3.5 Flash is interesting, but my first impression is mixed: sometimes it is fast, sometimes it is not, and for Angular development it does not yet feel like a real challenger to Opus 4.7, GPT 5.5, or Composer 2.5. I still need more hands-on time and better external benchmark data before I can recommend it with confidence. Gemini 3.5 Pro might become the more serious candidate here, especially if it combines stronger coding quality with more consistent speed.
But Alex, what about the new model(s)?
Only two days after publishing this post (on May 28, 2026), Anthropic released Claude Opus 4.8. So does that mean this post was already outdated two or three days later?
I don't think so.
There is probably some improvement from Opus 4.7 to Opus 4.8, and Anthropic's benchmark numbers are impressive. The new model, and the next ones after it, might beat other models such as GPT 5.5 on several benchmarks. But that does not change the main point of this post: benchmark wins are useful signals, not final answers.
For real Angular work, the best model is still the one that fits your workflow best. Try the new models when they arrive, but judge them in your own codebase, with your own tasks, your own tools, and your own review standards.
Agentic Engineering Workshop
This is also why I don't think about LLMs in isolation anymore: the model, the app, my Angular Guardrails, my Angular Coding Style Guide, the Angular Skills, and the review workflow belong together.
If you want to choose the right model for your Angular work – and actually put it to work on real modernization, refactoring, testing, and review tasks – join our Agentic Engineering Workshop, available in English and German.
In this workshop, advanced Angular developers learn how to move from vibe coding to traceable Agentic Engineering workflows: AI-ready project setup, guardrails, spec-first and plan-first workflows, UX and component prototyping, code review, testing, and brownfield refactoring.
- 🤖 Agentic Engineering Workshop – 2 days, remote
Conclusion
The real shift is not that these models can generate code. The real shift is that they can participate in the engineering workflow: asking questions, clarifying requirements, exploring trade-offs, and helping us move from vague intent to working Angular code.
For serious Angular work, my current recommendation is simple: start with Opus 4.7 when quality, architecture, and complex agentic work matter most. Use GPT 5.5 when you want a very strong all-rounder that is efficient, pleasant to work with, and great for writing, modernization, and focused implementation tasks.
Watch Composer 2.5 closely, especially if you already work in Cursor and care a lot about speed and cost. Treat Gemini 3.5 Flash as experimental for now, and revisit once Gemini 3.5 Pro ships.
As the Opus 4.8 update above already shows, this space changes too quickly for fixed rankings to stay perfect for long. So whatever model you choose, don't rely on benchmarks alone: the real test is still whether the model helps you ship better Angular code in your own codebase.
In the next post, I look at the other half of the story: which apps, IDE integrations, and agentic coding harnesses actually make these models useful in daily Angular work. After that, I go deeper into AI coding costs, what AI coding tools do with your code, and my personal agentic coding verdict.
Thank you for reading 🙏 this blog post was written by Alexander Thalhammer. For feedback, remarks or questions, please reach out to me ❤️