

Good domain boundaries help to make a software system maintainable in the long term. But how do you know whether the originally defined structure is still viable? How do you find out where improvements are needed? An obvious approach is to analyze the dependencies between the individual parts of your application. A forensic analysis goes further and discovers hidden patterns by taking historical data into account.
This article shows what information the forensic analysis of an Angular application can reveal from an architectural perspective. For this purpose, our open-source tool Detective is used. It is inspired by the ideas from the book Your Code as a Crime Scene and partially implements them. The analyzed example application can be found here.
The Example Application Examined
The example application used here is divided into two domains. A shared area also offers reusable technical aspects such as logging or authentication. The following figure illustrates this structure with a diagram Detective derived from the source code:

The connection between ticketing and shared is shown a little thicker, which indicates that there are more dependencies here than between booking and shared. Its tooltip text informs about the concrete number. At first glance, everything seems to fit: There are two separate domains that share a few technical implementations. A little more information emerges when you drill down into these three areas:
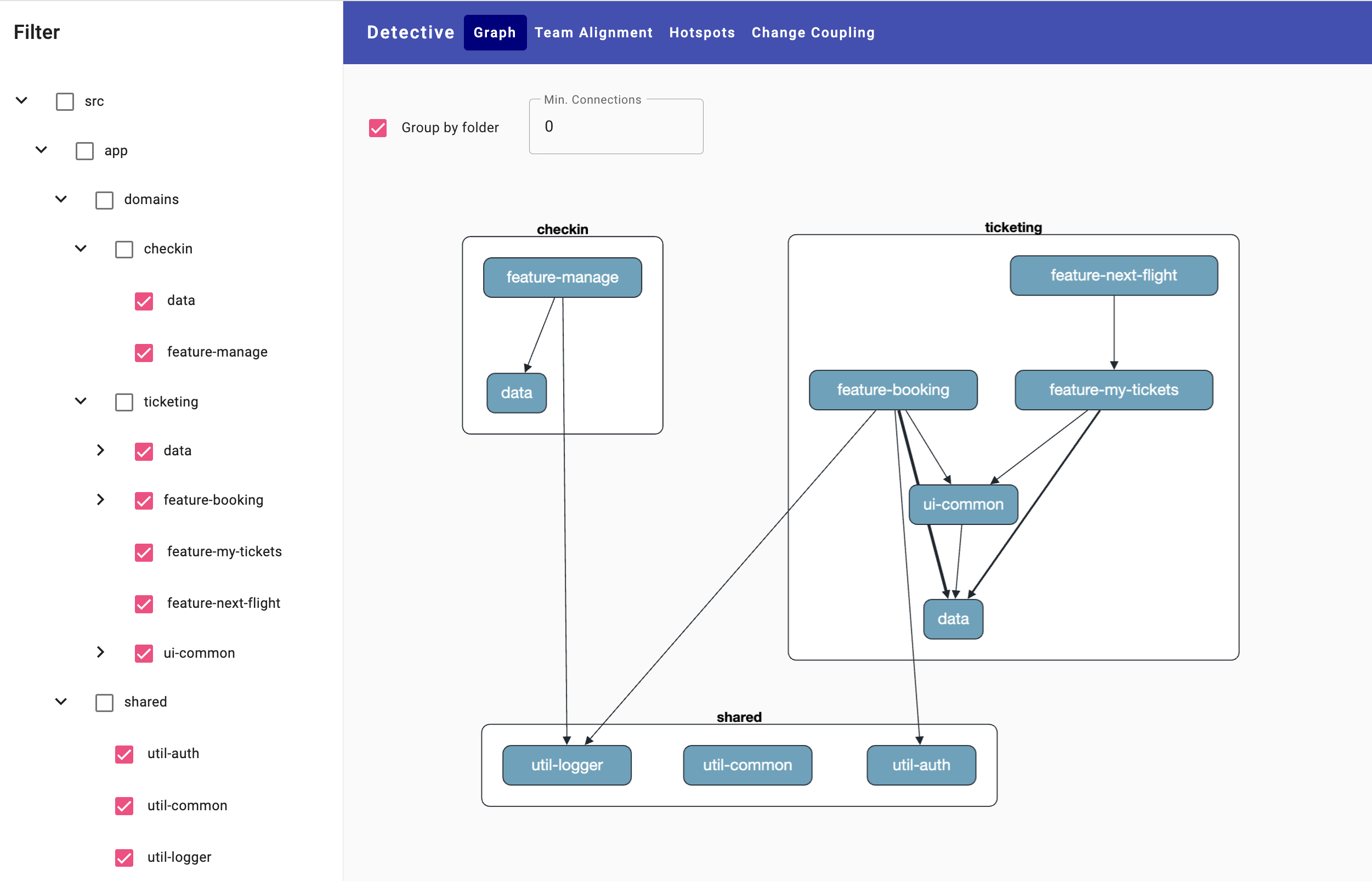
Here, you can see that there are more dependencies within the domains. This is also a good sign because it shows that these domains each deal with a related area of responsibility. This is referred to as high coherence, which ideally means that most changes within the domains are isolated and do not affect other domains.
Strictly speaking, this high level of coherence within the domains and the low level of coupling between the domains are two sides of the same coin. In both cases, the aim is to enable domains to evolve as independently as possible. Developers, therefore, do not have to constantly keep the overall system in mind. This reduces cognitive load and leads to more focus, fewer errors, and shorter lead times. Ideally, the domain cut also correlates with the team structure, resulting in self-sufficient teams that can each focus on their own domains.
Analyzing Layering
However, this first structural analysis also reveals a potential problem: the feature feature-next-flight depends on feature-my-tickets. This is not necessarily a bad thing, but it can lead to dependency chains and even cycles. To prevent this, domains are divided into several layers, each of which is only allowed to communicate with lower layers:
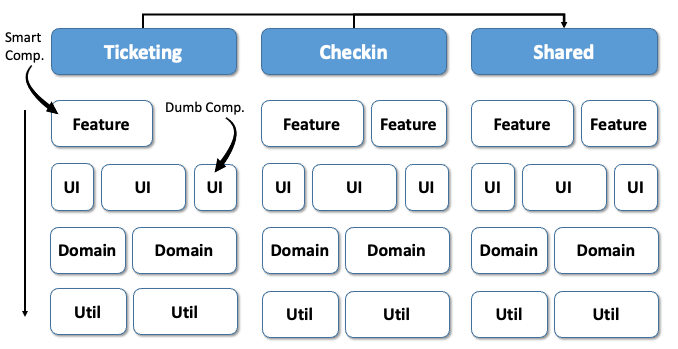
Here, we see the following layers:
- feature: Contains components that take care of use case control. These so-called smart components fulfill specific tasks and are, therefore, not designed for reusability.
- ui : Reusable use case-independent components. These are also called dumb components or presentational components.
- domain: Types that represent the received objects and Services that communicate with the backend.
- util: Auxiliary functions such as authentication or logging.
The layers shown here correlate with the ideas provided by the Nx team and have proven themselves in our projects, especially since they bring a good balance between benefit and overhead.
They can also be adapted to the respective project. For example, some customers decide to split the data layer into two layers: one takes care of data access and the other provides the associated types. In this case, dumb components only get access to the types, especially since they are not intended to communicate independently with the backend.
The functionality that feature-my-tickets wants to share with feature-next-flights in the case at hand could be placed in the form of dumb components and services in the ui and data layers. Alternatively, the layering could be softened a little, and feature components in domains could be allowed to access feature components in shared. Since communication, in this case, only runs in one direction, cycles are not possible. Another option would be to introduce another layer, e.g., sub-feature, between feature and ui.
The findings from the analysis of the project structure often lead to such discussions and thus to deliberate decisions for further development. The forensic methods described in the next sections provide additional information and discussion bases that go far beyond this.
Forensic Analysis for Architects: A Brief Overview
The ideas for forensic code analysis presented by Adam Tornhill in his book Your Code as a Crime Scene apply concepts from criminalistics to the examination of source code. It uses historical data from source code management to identify so-called hotspots in the application code - complex areas that are frequently changed. Hotspots can be indicators of architectural weaknesses that make the system unstable and difficult to maintain in the long term.
By taking the time dimension into account, even more hidden information about the further development of the architecture can be identified. One example of this is change coupling. This involves files that are frequently changed together and therefore have non-obvious dependencies on each other. This information helps in evaluating the current modularization.
Another example is analyzing the alignment between team structure and module structure. Such alignment allows teams to focus on specific parts of the application and work more autonomously, which in turn improves the quality of the code and reduces the risk of errors.
Using Detective
To analyze a project with Detective, execute the following commands in the root directory of the project:
npm i @softarc/detective -D
npx detectiveDetective assumes that Git is installed and set up for the project to be analyzed. The subdirectory .git is expected in the folder in which it is called.
Change Coupling
The coupling analyzed in the last section arose directly from the dependencies between EmcaScript modules. It can thus be deduced from the import and export statements in the source code. However, the first forensic analysis method I want to discuss here goes beyond this and reveals a less obvious kind of coupling: Change Coupling.
The idea is to identify files that are frequently changed together. Such files are logically coupled to each other and can highlight issues with you domain boundaries. For example, this type of coupling undermines the goal discussed above that most changes should be limited to one domain.
Here is an example from the analyzed demo project:

It becomes clear here that the coupling between the check-in and ticketing domains is not as low as assumed after the structural analysis discussed above. Knowing that perfect domain boundaries do not exist, this insight can be the basis for further discussion in investigation. The domain intersection can possibly be adjusted in favor of higher coherence and lower coupling, and we can aim for a better separation of concerns. The idea of the bounded context provided by Domain-driven Design can help here.
If the discussion reveals that the possible alternatives lead to more disadvantages, the decision will be made to maintain the current implementation. In this case, the analysis carried out has led to greater awareness of the necessary trade-offs.
Hotspots as an Indicator of Architectural Problems
If the same file has to be modified very frequently, this may indicate a problem with the architecture and the associated modularization. There may be a central component on which too many domains depend. If a component is frequently edited for different reasons, it is likely that it has too many tasks. In addition, it is meanwhile known that high code churn - many changes to the same files - leads to a higher error rate.
However, it obviously makes a difference whether a simple file or a complex file is changed often. Let's imagine a file with information about the available menu items. This file gets a few additional lines with each new feature. This means that there is a high level of code churn. Nevertheless, this is not critical because the structure of the file itself is not very complex.
Tornhill recommends weighting the code churn of a file with its complexity. He also notes that it doesn't really matter which complexity metric you choose. He refers to a study that examined the brain activity of developers while reading source code. To put it bluntly, this study concluded that complexity metrics are not particularly good at predicting the complexity of source code. This finding probably also corresponds to the gut feeling of many practitioners.
An interesting criterion that, according to this study, affects the comprehension of source code is the size of the vocabulary used, i.e., the number of variables, functions, classes, etc. Another criterion that seems to correlate at least partially with the vocabulary size is the length of the code being examined. This is why Tornhill uses Lines of Code as a measure of complexity in the book mentioned at the beginning. In his product Code Scene, however, he uses McCabe's cyclomatic complexity. This classic and widely used metric measures the number of paths that lead through the program code. Detective supports both metrics.
By multiplying the churn rate by a complexity measure, the hotspot analysis provides additional context for identifying problematic areas of code. The resulting metric is called Hotspot Score. A higher hotspot score indicates potentially riskier areas of code. There is no general statement as to which score indicates a serious problem. Rather, the hotspot score provides a suggestion for prioritization. Areas with higher values should be examined more closely.
The following figure shows the result of the hotspot analysis of the demo application examined here:

Due to its focus on architecture, Detective initially aggregates the hotspots found at module level. This means that you can see at a glance which domain or module contains how many files that exceed the specified score. Average values were deliberately omitted here to prevent many non-critical files from concealing the presence of some critical ones. When you click on one of the modules, the files found appear.
The hotspots discovered for our demo application do not seem to be of much concern. Two to three changes in total and a cyclometric complexity of 6 or less at the file level do not provide a serious basis for a panic reaction.
Team Alignment and Conway's Law
As early as 1968, the American computer scientist Melvin Conway discovered that the structure of applications reflects the communication structures of the developers. A common, vivid explanation of this observation, known as Conway's Law, goes something like this: If three teams develop a compiler together, you end up with a three-phase compiler.
That's why it makes sense to align the team structure with the desired software architecture, which is also known as the Inverse Conway Maneuver. For example, if one team is responsible for implementing a domain, this promotes the desired low coupling between the individual domains. The focus on one domain also reduces the cognitive load.
Even if the team structure officially corresponds to the domain average, this does not necessarily mean that this alignment is actually practiced. To identify this discrepancy, an analysis of the commits is a good way to see whether the individual teams can actually focus on their domains.
To do this, the user names used in source code management must first be linked to the individual teams. If Detective is used, a configuration file must be adapted for this purpose. The necessary details can be found in the Readme.
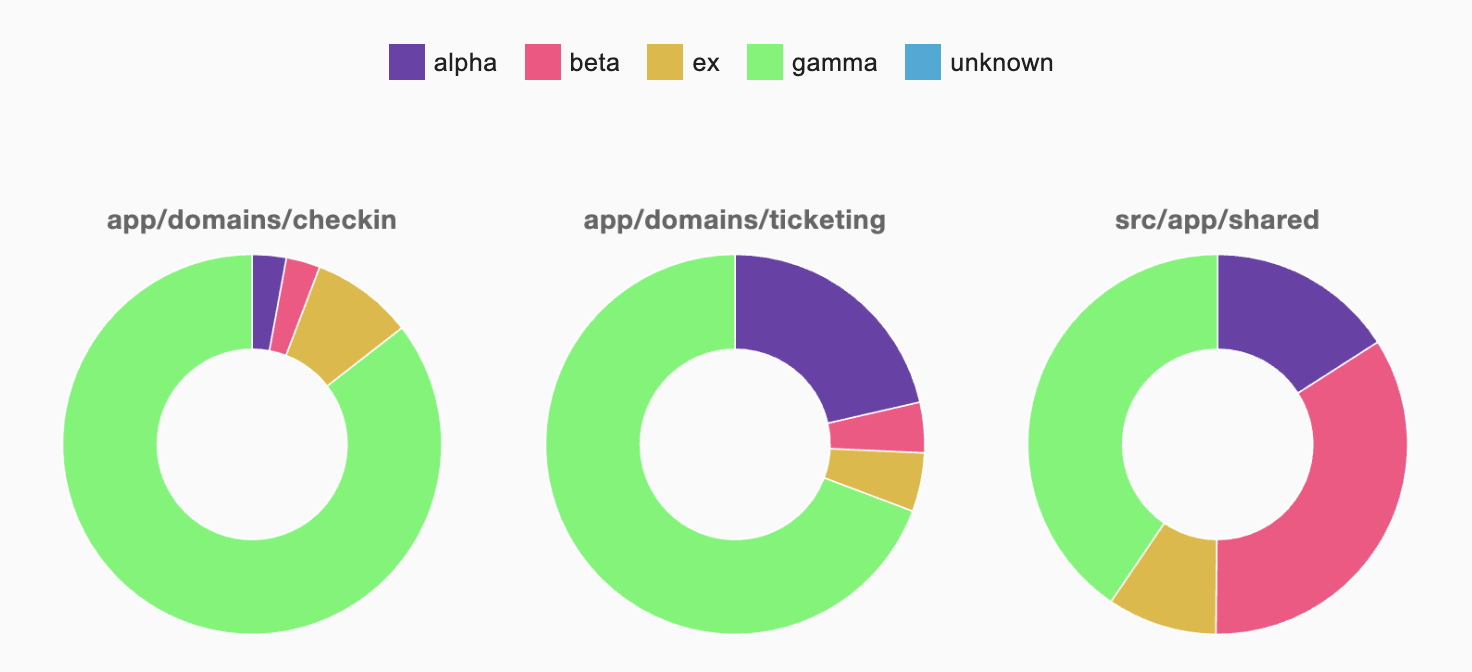
When analyzing our demo application, we see the correlation between teams and domains as well as the shared area:

Unfortunately, there is no clear alignment between the teams and the domains. It seems more like the Alpha and Beta teams support the Gamma team. This situation should be questioned. Perhaps another team structure can be found that correlates better with the domain boundaries. But it could also be that the domain boundaries need to be adjusted.
Other reasons are adherence to previous organizational structures but also task distribution between teams based on technical considerations. Historical factors may also lead to the discrepancy discovered here. For example, the Gamma team may have started development before the other teams joined, and the Alpha team later took over the ticketing domain. This hypothesis can be quickly tested by limiting the analysis period.
Since the shared area is not a homogeneous unit but a loose collection of reusable modules, the analysis should be repeated at the level of these modules. This makes it possible to see whether there are lead authors here. However, more important than a strict team /code alignment for technical reusable modules are clear responsibilities, which, among other things, prevent contributions from different teams from leading to breaking changes.
By assigning former team members to their own artificial team, you can also find out whether there has been a loss of knowledge due to their departure:
This approach can also be extended to what-if considerations to determine whether knowledge needs to be better distributed within the teams.
More on this: Angular Architecture Workshop (online, interactive, advanced)
Become an expert for enterprise-scale and maintainable Angular applications with our Angular Architecture workshop!
All Details (English Workshop) | All Details (German Workshop)
From Detective to Code Scene
It will come as no surprise that the forensic analysis described here can be further improved. For example, commits that originate from the same feature branches or refer to the same ticket ID could be grouped together. This prevents change coupling from being overlooked if the individual domains are changed with different commits.
When analyzing hotspots, one could also consider other factors, such as how knowledge is distributed among team members about critical areas. If only one person knows the source code in the hotspot, this increases its criticality.
It's also desirable to see how the system has evolved over time to determine whether the situation around coupling, team alignment, and hotspots has improved over the last few iterations.
The commercial product Code Scence, developed by Adam Tornhill, also implements these options and further analyses, which reveal many other insights.
Critical Review
It is astonishing what hidden patterns can be revealed through forensic analysis and how well they fit with typical themes from the field of software architecture: coupling, coherence, and team alignment.
Despite all the euphoria, however, it must be recognized that this type of analysis is only a small piece of the puzzle and is no substitute for a qualitative architecture evaluation. For example, we also need to assess whether the current architecture actually supports the existing architectural goals, e.g., in terms of performance, security, or usability, whether deliberate decisions have been made for key issues such as state management or authentication, whether defined patterns are implemented correctly and still make sense, and whether the original assumptions about trade-offs have proven correct.
Furthermore, forensic analysis is also no replacement for stakeholder interviews such as interviews with product managers or developers. In all the architecture reviews I conducted, it was clear that developers have a strong intuition for areas that need improvement.
The values determined are also not suitable as targets. Rather, they point to certain subtle areas that should be examined more closely.
Summary
Forensic analysis methods look not only at the current source code but also at the historical development of a project recorded in source code management systems. This makes it possible to discover non-obvious patterns.
Change coupling provides information about files that are frequently changed together and a hotspot analysis identifies complex areas with a high churn. It also helps to find out how well the team structure fits the domain boundaries and the selected modularization.
Although these analyses do not replace a qualitative architecture evaluation, they still provide a quick overview of critical areas that should be examined, questioned, and discussed.
