

Coding-Agents schreiben heute Code schneller, als wir ihn lesen können. Das ist großartig für die Geschwindigkeit – und brandgefährlich für die Architektur. Denn ein Sprachmodell optimiert standardmäßig auf „funktioniert", nicht auf „passt zu unserer Zielarchitektur". Wenn niemand gegensteuert, landet der schnell generierte Datenzugriff direkt in der Komponente, wandern Querverweise zwischen Domänen ein und weicht die mühsam etablierte Struktur Commit für Commit auf.
Die gute Nachricht: Genau diese Leitplanken lassen sich heute so beschreiben, dass der Coding-Agent sie nicht nur kennt, sondern ihnen auch folgt – und dass er bei Verstößen ein deterministisches, maschinelles Feedback bekommt, mit dem er sich selbst korrigiert.
AI-assisted Coding braucht Architektur als ausführbaren Vertrag: dokumentiert in Rules, aktiviert über aufgabenspezifischen Kontext, geprüft durch Sheriff und zurückgespielt über Hooks.
In diesem Artikel zeige ich, wie das in der Praxis aussieht. Es geht darum, Kontext für die Architektur bereitzustellen, Architektur-Checks wie Sheriff in die Feedback-Loop der AI zu integrieren und das Ganze so aufzusetzen, dass es über mehrere Plattformen wie Cursor AI, Claude Code, Codex (GPT) oder Googles Antigravity CLI hinweg funktioniert. Wir binden die offiziellen Angular Skills und den MCP-Server der Angular CLI ein, berücksichtigen den NgRx Signal Store, ergänzen eigene Skills und beziehen am Ende auch ADRs und weitere dokumentierte Entscheidungen mit ein.
📂 Source Code (Branch: ai-arc)
Zielarchitektur: Domänen und Layer in Angular
Bevor eine AI eine Architektur einhalten kann, müssen wir diese Architektur definieren. Unser Beispiel gliedert die Anwendung in Domänen: Domänen reduzieren die kognitive Last, weil man sich beim Arbeiten an einem Feature nur um einen überschaubaren Ausschnitt kümmern muss, und sie unterstützen die Teamorganisation, weil sich Verantwortlichkeiten klar zuschneiden lassen.
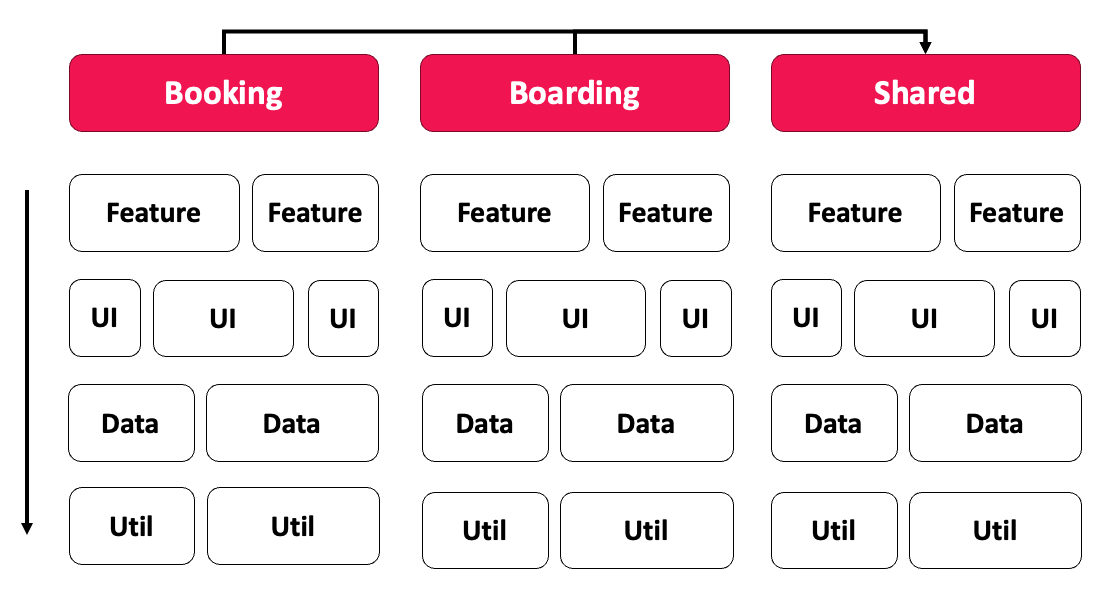
Die Matrix zeigt das Prinzip. Jede Spalte ist eine Domäne, jede Zeile ein Layer. Ein Feature ist ein fachlicher Anwendungsfall, typischerweise mit Smart Components, die den Use Case orchestrieren. UI enthält wiederverwendbare, „dumme" Komponenten. Data kümmert sich um Datenzugriff und Datenmodelle, Util um technische Hilfsfunktionen. Quer dazu gibt es eine Shared-Domäne für Code, den mehrere Domänen benötigen.
Entscheidend sind die erlaubten Zugriffe: Layer dürfen nur von oben nach unten aufeinander zugreifen (feature → ui → data → util), und Domänen greifen nicht direkt aufeinander zu. Wer Code aus einer anderen Domäne braucht, nutzt entweder die Shared-Domäne oder eine API, die gezielt Zugriff auf ausgewählte Teile einer Domäne bietet.
Darauf aufbauend setzen wir auf Feature Slicing. Die Idee ist Lokalität: Code, der nur zu einem Feature gehört, lebt auch im Feature-Ordner – inklusive feature-lokaler dumb Components, Stores und Hilfsfunktionen. Das hält die kognitive Last gering, weil zusammengehöriger Code beieinander liegt. Der Nachteil ist ebenso real: Wird lokaler Code plötzlich woanders gebraucht, muss er refactored, also in einen globaleren Bereich verschoben werden. Wir werden später sehen, wie sich genau dieses Verschieben mit AI-assisted Coding gut automatisieren lässt.
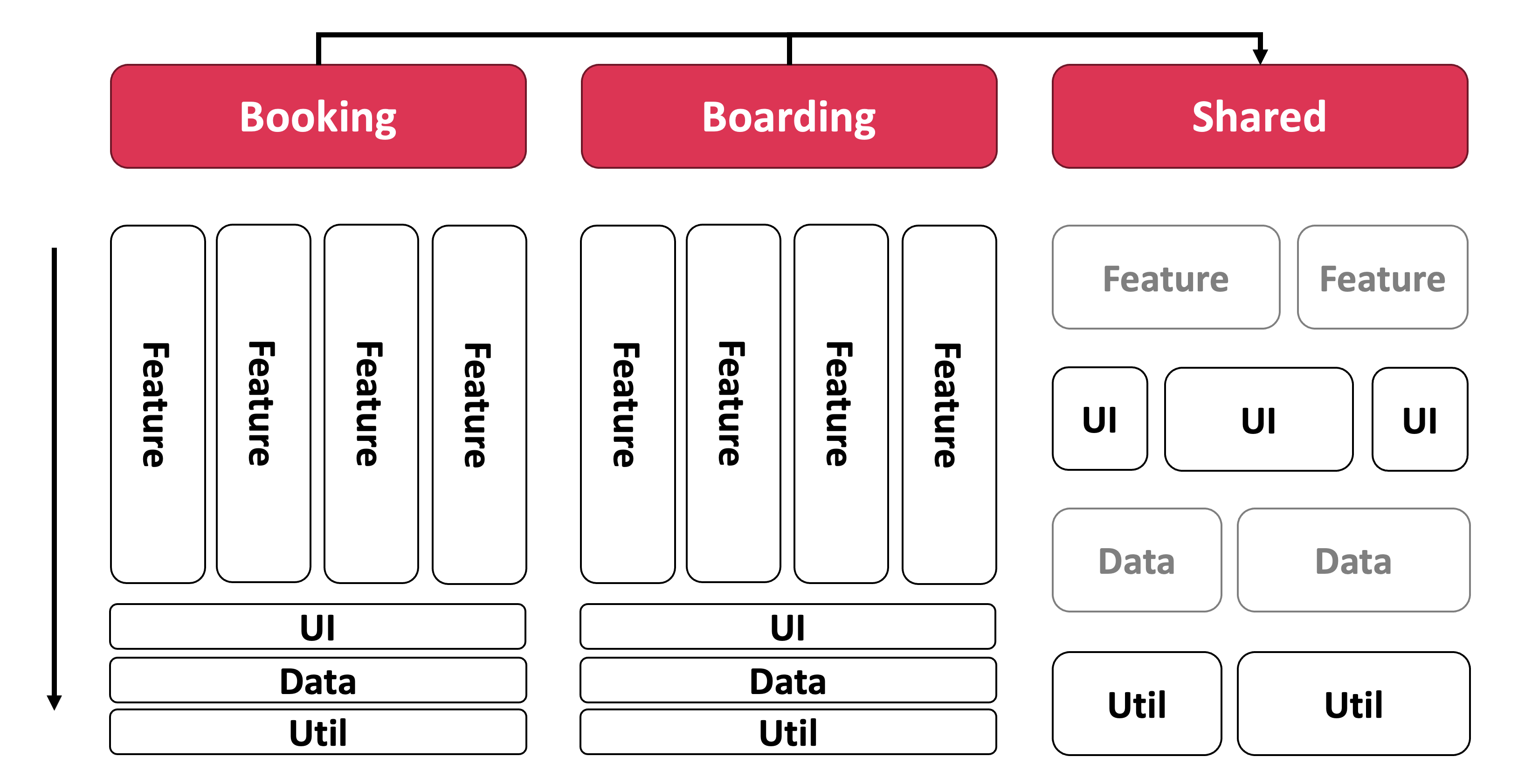
Das Bild macht deutlich, dass Feature Slicing gar nicht so weit von der reinen Matrix entfernt ist. Es erlaubt schlicht zusätzlich feature-lokale UI-, Data- und Util-Bausteine, die erst dann in einen tieferen, gemeinsamen Layer wandern, wenn sie tatsächlich von mehreren Features benötigt werden.
Architektur-Matrix mit Sheriff validieren
Eine Architektur, die nur in einer Präsentation existiert, hält keinem Sprint stand. Deshalb erzwingen wir die Matrix mit Sheriff. Sheriff vergibt Tags an Ordner – etwa domain:ticketing und type:data – und definiert Regeln, welche Tags auf welche zugreifen dürfen. Hält man sich nicht daran, gibt es einen Linting-Fehler: direkt beim Tippen in der IDE und auf der Konsole.
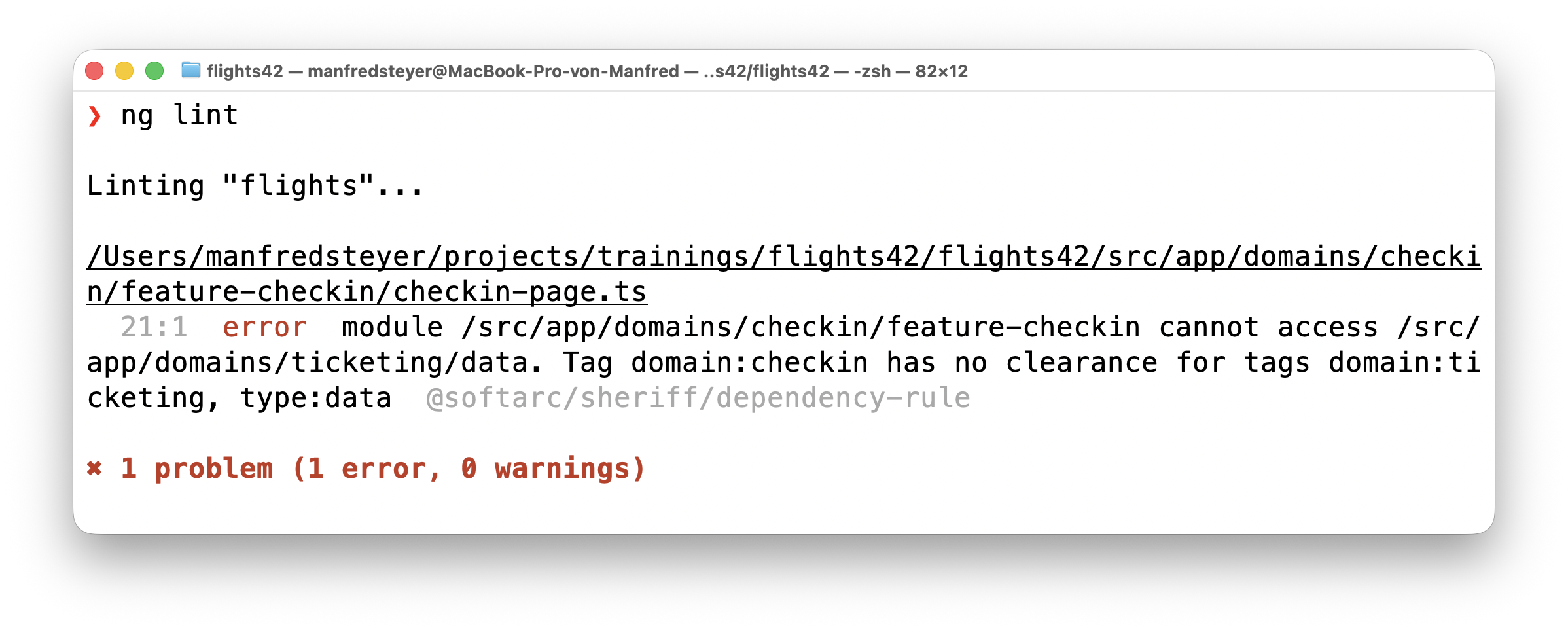
Die Meldung ist erfreulich konkret: Das Modul domains/checkin/feature-checkin darf nicht auf domains/ticketing/data zugreifen, weil domain:checkin keine Freigabe für domain:ticketing, type:data hat. Genau diese Präzision ist der Schlüssel für den nächsten Schritt – denn ein solcher Fehler ist nicht nur Feedback für Entwicklerinnen und Entwickler, sondern auch ein hervorragendes, deterministisches Feedback für das Sprachmodell. Wir werden gleich sehen, wie der Coding-Agent diese Meldung aufgreift und seinen Code selbstständig korrigiert.
Wie sich eine solche Architektur mit Sheriff und Standalone Components im Detail aufsetzen lässt, beschreibt der Artikel Modern Architectures with Angular – Strategic Design with Sheriff.
Kontext bereitstellen: Rules
Ein Coding-Agent ist nur so gut wie der Kontext, den er bekommt. Ohne explizite Vorgaben rät das Modell – und es rät im Zweifel den Mainstream-Stil aus seinen Trainingsdaten, nicht unsere Konventionen. Kontext ist also kein nettes Extra, sondern die Voraussetzung dafür, dass generierter Code überhaupt zu unserer Architektur passt.
Den Einstieg liefert Angular selbst. Das Framework generiert eine AGENTS.md mit den wichtigsten Eckpunkten für modernes Angular – Signals, Standalone Components, inject(), native Control Flow und vieles mehr. Das ist ein ausgezeichneter Ausgangspunkt, den wir nicht neu erfinden müssen.
Cursor AI liest seine Vorgaben aus dem Ordner .cursor/rules. Damit wir keine Regeln duplizieren, verweist unsere Cursor-eigene Regel cursor.mdc auf die AGENTS.md als maßgebliche Quelle:
---
alwaysApply: true
---
Always follow the guidelines defined in the `AGENTS.md` file in the project root.
It is the authoritative source for coding standards, conventions, and best practices.
In case of conflicts, the rules in `AGENTS.md` take precedence.Das alwaysApply: true im Frontmatter sorgt dafür, dass diese Regel bei jeder Anfrage gilt – und der eigentliche Inhalt verweist nur noch auf die AGENTS.md. Damit zeichnen sich bereits klare Rollen für die einzelnen Artefakte ab:
AGENTS.mdenthält die roten Linien und kurze Verweise – nicht die vollständigen Detailregeln.docs/architecture-boundaries.mdist die Source of Truth für Domains, Layering, Feature Slicing, Shared Code, öffentliche APIs und Sheriff-Regeln.docs/architecture-state-management.mdist die Source of Truth für Store- und State-Management-Konventionen.
Die vollständigen Detailregeln sollen also nicht in der AGENTS.md dupliziert werden. Kurz gefasst:
Docs enthalten die verbindlichen Architektur- und Coding-Regeln. AGENTS.md nennt die wichtigsten roten Linien und verweist auf die relevanten Regeln. Aufgabenspezifischer Kontext wird nur dann herangezogen, wenn die jeweilige Aufgabe ihn benötigt.
Dahinter steckt eine bewusste Entscheidung über die Kontextgröße: Je mehr dauerhaft im Prompt liegt, desto höher sind Kosten, Ablenkung und das Risiko für Kontextverschmutzung. Deshalb gehören nur kurze Always-on-Regeln in die AGENTS.md bzw. in always-on Rules. Die detaillierten Regeln bleiben in docs/architecture-boundaries.md und docs/architecture-state-management.md und werden bei passenden Aufgaben gelesen oder über Rules, Prompts oder später über Skills aktiviert. Diesen Gedanken greifen wir im Abschnitt zu Skills wieder auf.
In Cursor können Rules dauerhaft gelten, über Dateimuster greifen, anhand ihrer Beschreibung vom Agenten ausgewählt oder explizit referenziert werden. Damit bewegen sich .mdc-Dateien bereits in Richtung aufgabenspezifischer Kontextsteuerung: Kurze rote Linien bleiben immer sichtbar, detaillierte Regeln werden nur dann aktiviert, wenn die Aufgabe sie benötigt. Konkret verweisen die .mdc-Dateien unter .cursor/rules auf docs/architecture-boundaries.md und docs/architecture-state-management.md und helfen dem Agenten, sie bei passenden Aufgaben zu berücksichtigen.
Bei anderen Werkzeugen wie Claude Code erreichen wir denselben Effekt über Prompting: In lokalen Instruktionsdateien sagen wir dem Agenten, was wann zu laden ist – etwa docs/architecture-boundaries.md bei strukturellen Änderungen und docs/architecture-state-management.md bei Store-Aufgaben. Statt jede Detailregel dauerhaft mitzuführen, wird so die jeweils passende Regel zur jeweiligen Aufgabe herangezogen. Die konkrete Umsetzung über CLAUDE.md und src/CLAUDE.md sehen wir uns weiter unten an.
Die vollständigen Dateien lassen sich bei Bedarf auf GitHub nachschlagen: architecture.mdc, docs/architecture-boundaries.md und docs/architecture-state-management.md.
Allgemeine Architektur-Regeln
Bei den Architekturregeln ist entscheidend, dass wir die heiklen Stellen unmissverständlich festhalten. Die wichtigsten Regeln in Kurzform:
- Die Sheriff-Konfiguration darf nur auf ausdrücklichen Wunsch geändert werden. Sie darf insbesondere nicht aufgeweicht werden, nur damit der Linter zufrieden ist.
- Feature Slicing: Feature-lokaler Code ist zu bevorzugen. Wird er später auch anderswo gebraucht, ist er in einen tieferen Layer zu verschieben.
- Neue Domänen dürfen nur auf ausdrücklichen Wunsch hinzugefügt werden. Das Modell darf neue Domänen aber vorschlagen.
- Code in den Shared-Bereich verschieben ist nur erlaubt, wenn die Benutzerin oder der Benutzer zustimmt oder es ausdrücklich anfordert. Dabei gilt: Shared ist eine bewusste Architekturentscheidung, kein Ausweichordner für Importprobleme.
- Dasselbe gilt für das Veröffentlichen von Code für andere Domänen über APIs. In diesem Fall erlauben zusätzliche Sheriff-Regeln den Zugriff auf eine
api/index.tsmit ausgewählten Exporten in einer Nachbardomäne. - Neuer Code für neue Use Cases soll sich am Aufbau einiger bereits existierender, guter Referenz-Use-Cases orientieren (etwa
FlightSearchundFlightEdit). Das hat sich in der Praxis als überraschend effektiv erwiesen.
Spezifische Regeln für State Management
Auch die Regeln für den Signal Store sind explizit. Sie geben unter anderem vor:
- Aus dem NgRx Toolkit sind
withResource,withMutationsund der Dev-Tools-Support (withDevtools) zu nutzen. - Der Store delegiert den Datenzugriff an einen Datenzugriffsservice und greift nicht selbst auf das Backend zu.
- Es gibt klar abgegrenzte Arten von Stores: für die Entitäten einer Suchliste (
<Entity>SearchStore), für die Entität einer Detailansicht (<Entity>DetailStore), für Lookup-Entitäten bzw. Vorschlagswerte (<Feature>LookupStore) und für UI-State. - Ein Store erhält nur dann Zugriff auf einen anderen Store, wenn die Benutzerin oder der Benutzer zustimmt.
Namenskonventionen
Nicht jede Vorgabe lässt sich sinnvoll über Layering und Sheriff abbilden. Würde man es versuchen, würde die Konfiguration schnell unübersichtlich. Deswegen setzen wir zusätzlich auf Namenskonventionen, die sich gut beschreiben und vom Modell leicht prüfen lassen.
Ein gutes Beispiel ist der Zugriff auf den Store. Nur Smart Components dürfen einen Store nutzen, und Smart Components erkennt man in unserem Projekt an den Suffixen Page, Search, Detail und Edit – etwa FlightSearch oder FlightEdit.
Diese Konventionen sind ebenfalls in den Rules festgehalten. Gerade jetzt, wo Komponenten in modernem Angular nicht mehr den wenig aussagekräftigen Standard-Suffix Component tragen, lohnt es sich, Suffixe für solche Semantiken zu nutzen – für Mensch und Maschine.
Kontext bei Bedarf: Angular Skills und MCP-Server
Würden wir den gesamten Kontext immer in den Prompt packen, wäre dieser schnell überladen, teuer und unübersichtlich. Bei den Rules nutzen wir fallspezifisches Laden bereits teilweise: in Cursor etwa über Dateimuster, Beschreibungen oder explizite Referenzen, bei Claude Code über entsprechende Prompting-Regeln. Skills führen diese Idee weiter, indem sie aufgabenspezifisches Wissen und wiederkehrende Abläufe bündeln.
Skills kapseln also aufgabenspezifisches Wissen und konkrete Arbeitsabläufe. Je nach Tool können sie automatisch oder explizit aktiviert werden. Daraus ergibt sich eine klare Arbeitsteilung:
Docs enthalten die verbindlichen Architektur- und Coding-Regeln. Skills beschreiben, wie ein Agent bei bestimmten Aufgaben vorgehen soll. AGENTS.md nennt die wichtigsten roten Linien und verweist auf die relevanten Regeln.
Skills verweisen damit auf die Docs, duplizieren sie aber nicht: docs/architecture-boundaries.md und docs/architecture-state-management.md bleiben die verbindlichen Detailregeln, während ein Skill den passenden Arbeitsablauf dazu beschreibt.
Die Angular-Community stellt offizielle Skills bereit, die regelmäßig an die jeweils aktuelle Framework-Version angepasst werden. Wir installieren sie mit der Skills-CLI:
npx skills add https://github.com/angular/skillsDas legt die Skills angular-developer und angular-new-app im Ordner .agents/skills/ ab – einer Konvention, die sich werkzeugübergreifend etabliert hat. Eine skills-lock.json hält fest, welche Version installiert ist, sodass sich Aktualisierungen nachvollziehbar einspielen lassen.
Genau dieses Muster lässt sich auf unsere eigenen Regeln übertragen. Für die State-Management-Konventionen aus docs/architecture-state-management.md bietet sich zusätzlich ein task-spezifischer signal-store-Skill an. Die docs/architecture-state-management.md bleibt dabei die verbindliche Quelle für Store-Konventionen; der Skill verweist darauf und beschreibt den konkreten Ablauf für typische Aufgaben: wann ein neuer Store sinnvoll ist, welcher Store-Typ zu wählen ist, wo der Store liegen soll, welche bestehenden Stores als Referenz dienen und welche Checks nach der Änderung auszuführen sind. Die Regel selbst bleibt also in der Projektdokumentation; der Skill beschreibt, wie der Agent bei Store-Aufgaben konkret vorgehen soll.
Dasselbe Muster lässt sich übrigens auch auf die Architekturregeln anwenden: Statt docs/architecture-boundaries.md nur über Dateimuster-Rules und Prompting zu aktivieren, könnte ebenso ein eigener Architektur-Skill diese Aufgabe übernehmen und bei strukturellen Änderungen anschlagen. Entscheidend bleibt die Rollentrennung – der Skill beschreibt den Ablauf und verweist auf die Doku als verbindliche Quelle, er wird nicht selbst zur Source of Truth. Die Regel lebt also weiterhin in docs/architecture-boundaries.md, der Skill zeigt nur darauf.
Zusätzlich ist der MCP-Server der Angular CLI nützlich. MCP (Model Context Protocol) ist ein offener Standard, über den ein Coding-Agent auf externe Werkzeuge und Wissensquellen zugreifen kann. Der Angular-MCP-Server liefert dem Agenten unter anderem gut kuratierte Beispiele und Zugriff auf die aktuelle Dokumentation – ideal, um Best Practices auch dann zu treffen, wenn die Trainingsdaten des Modells schon etwas älter sind.
In Cursor AI richten wir den Server über die Datei .cursor/mcp.json ein:
{
"mcpServers": {
"angular-cli": {
"command": "npx",
"args": ["-y", "@angular/cli", "mcp"]
}
}
}Damit steht dem Agenten der Angular-MCP-Server zur Verfügung, sobald er ihn benötigt.
Architektur-Checks per Hook in die AI-Feedback-Loop bringen
Bis hierher haben wir dem Modell viel beigebracht. Aber Wissen allein reicht nicht – wir brauchen ein deterministisches Sicherheitsnetz, das jede Runde des Agenten überprüft. Genau dafür gibt es Hooks.
Ein Stop-Hook greift, wenn der Agent meint, fertig zu sein, und führt vorher ein Node-Skript aus, das Linter, Tests und Build laufen lässt. Über den Linter ist dabei auch Sheriff eingebunden – unsere Architektur-Matrix wird also bei jeder Runde maschinell geprüft.
Wir trennen dabei von Anfang an die eigentliche Prüflogik von der werkzeugspezifischen Verdrahtung: Ein gemeinsamer Prüfkern liefert ein neutrales Ergebnis, und ein schlankes Hook-Skript pro Werkzeug übersetzt es in dessen Konventionen. So lässt sich das Setup im nächsten Abschnitt mühelos auf mehrere Coding-Agents ausweiten.
Die eigentliche Prüflogik bildet den Kern und liegt in scripts/ci-checks.mjs. Es kennt nur die Checks selbst – nichts von Exit-Codes oder stdout/stderr:
import { execSync } from 'node:child_process';
const fastSteps = [
'npx ng lint flights',
'npm run test:arch',
'npm run test:scripts',
];
const fullOnlySteps = [
'npx ng test flights --configuration ci',
'npx ng build flights',
];
// Runs the CI steps in order and stops at the first failing one.
// Returns a discriminated result instead of throwing so callers can map it
// to whatever their environment expects (exit code, JSON payload, ...).
export function runChecks({ full = false, capture = false } = {}) {
const steps = full ? [...fastSteps, ...fullOnlySteps] : fastSteps;
for (const step of steps) {
try {
execSync(step, capture ? { encoding: 'utf8' } : { stdio: 'inherit' });
} catch (error) {
const out = capture
? [error.stdout, error.stderr].filter(Boolean).join('\n').trim()
: '';
return {
status: 'error',
message: `Check failed: ${step}\n\n${out || error.message}`,
};
}
}
return { status: 'success' };
}runChecks führt die Schritte nacheinander aus und unterscheidet bewusst zwischen schnellen Checks (Lint inklusive Sheriff sowie Architektur- und Skript-Tests) und den teureren Schritten (Unit-Tests und Build), die nur bei full hinzukommen. Statt im Fehlerfall eine Exception zu werfen, liefert die Funktion ein diskriminiertes Ergebnis zurück – { status: 'success' } oder { status: 'error', message } mit der eingesammelten Ausgabe. So kann jeder Aufrufer das Ergebnis genau in das übersetzen, was seine Umgebung erwartet (Exit-Code, JSON-Payload …). Über capture steuern wir, ob diese Ausgabe für die spätere Rückmeldung an das Modell gesammelt (capture: true) oder direkt auf die Konsole durchgereicht wird.
Den werkzeugspezifischen Teil übernimmt pro Coding-Agent ein eigenes, schlankes Hook-Skript: Es ruft runChecks auf und übersetzt das Ergebnis in die Konventionen seines Werkzeugs. Geteilt wird neben dem Prüfkern nur eine winzige Hilfsfunktion, die den Kontext des Werkzeugs von stdin liest (scripts/hooks/read-input.mjs):
import process from 'node:process';
export async function readInput() {
const chunks = [];
for await (const c of process.stdin) {
chunks.push(c);
}
try {
return JSON.parse(Buffer.concat(chunks).toString() || '{}');
} catch {
return {};
}
}Für Cursor sieht das Hook-Skript so aus (scripts/hooks/cursor-stop-hook.mjs):
import process from 'node:process';
import { runChecks } from '../ci-checks.mjs';
import { readInput } from './read-input.mjs';
const input = await readInput();
if (input.status !== 'aborted') {
const result = runChecks({ capture: true });
if (result.status === 'error') {
process.stdout.write(JSON.stringify({ followup_message: result.message }));
process.exit(0);
}
}
process.stdout.write('{}');
process.exit(0);Hier zeigt sich Cursors Konvention unmittelbar: Wurde der Lauf abgebrochen (status === 'aborted'), überspringt das Skript die Checks. Andernfalls läuft runChecks; meldet es einen Fehler, wandert die Fehlermeldung als followup_message in ein JSON-Objekt auf stdout – genau dieses Feld spielt Cursor dem Agenten als nächste Aufgabe zurück. In allen anderen Fällen liefert der Hook ein leeres JSON-Objekt. Der Exit-Code bleibt durchweg 0; Cursor entscheidet anhand der Ausgabe, wie es weitergeht.
Registriert wird der Hook in .cursor/hooks.json – wir verweisen nun auf das Cursor-Hook-Skript statt direkt auf das Prüfskript:
{
"version": 1,
"hooks": {
"stop": [
{
"command": "node scripts/hooks/cursor-stop-hook.mjs",
"timeout": 600,
"loop_limit": 3
}
]
}
}Schlägt einer der Checks fehl – etwa weil Sheriff einen Architekturverstoß meldet, ein Test rot ist oder der Build bricht –, geht der Agent in eine neue Runde. Er bekommt die Fehlermeldung als Input und versucht, sie zu beheben. Das loop_limit von drei begrenzt dabei, wie oft sich diese Schleife wiederholt, damit der Agent nicht endlos kreist.
Das angesprochene Staffeln der Checks ist im Skript bereits angelegt: Standardmäßig laufen nur die schnellen Checks wie Lint und Sheriff, die teureren Schritte – vollständige Tests und Build – kommen erst über full hinzu, etwa bei größeren Änderungen oder vor dem Merge. So bleibt das Sicherheitsnetz erhalten, ohne dass jede Runde unnötig teuer wird.
Dass es sich um ein Node-Skript handelt, ist eine bewusste Entscheidung: So läuft derselbe Check plattformunabhängig unter macOS, Linux und Windows.
Ein kleiner, aber wichtiger Unterschied im Verhalten der Werkzeuge: Cursor meldet sichtbar, wenn das Skript ausgeführt wird. Claude Code tut das nicht – dort bekommt man es nur dann mit, wenn ein Fehler auftritt.
Modern Angular
Mehr zu Signal Forms und moderner Angular-Architektur findest du in meinem neuen eBook Modern Angular. Es behandelt Signals, Architektur, Testing, KI-Assistenten und praxistaugliche Lösungen für moderne Business-Anwendungen.

Cursor AI und Claude Code aus einer Quelle der Wahrheit versorgen
Es ist nicht unüblich, dass Entwickler:innen ihre Werkzeuge selbst wählen dürfen. Und genau hier lauert ein praktisches Problem: Unterschiedliche Umgebungen erwarten Rules, Skills und MCP-Server in unterschiedlichen Ordnern und unter unterschiedlichen Dateinamen. Bei Claude Code etwa liegen Rules in CLAUDE.md, Skills unter .claude/skills/ und MCP-Server werden in der .mcp.json konfiguriert.
Wir wollen aber eine Quelle der Wahrheit behalten, statt jede Vorgabe mehrfach zu pflegen. Die Lösung hängt vom jeweiligen Artefakt ab.
Bei den Rules lösen wir es elegant über Verweise: Die CLAUDE.md im Projekthauptverzeichnis besteht im Kern nur aus einem Verweis auf die AGENTS.md:
@AGENTS.mdAußerdem verweist eine src/CLAUDE.md auf die Architektur-Dokumentation. So gibt es weiterhin nur eine maßgebliche Quelle, auf die alle Werkzeuge zeigen.
Before changing application or library code here, read `docs/architecture-boundaries.md` and apply the architecture rules.
If the change touches state management, also read `docs/architecture-state-management.md` when it exists.
Do not bypass documented domain boundaries. Prefer small, focused changes.Das ist die konkrete Umsetzung des bereits angesprochenen Prompting-Ansatzes: Statt „lies immer alle Architekturregeln" formulieren wir die Vorgabe fallspezifisch. Sinngemäß heißt das: Nutze docs/architecture-boundaries.md, wenn du strukturelle Änderungen machst – etwa an Domains, Layers, Imports, Shared Code, öffentlichen APIs oder Sheriff-Regeln. Nutze docs/architecture-state-management.md, wenn du Stores erstellst oder änderst. So liegt nicht jede Detailregel dauerhaft im Kontext, sondern wird bei der passenden Aufgabe herangezogen.
Das folgende Bild fasst zusammen, wie Claude Code und Cursor AI ihren Kontext beziehen: Beide laden ihre Einstiegs-Rules (CLAUDE.md bzw. cursor.mdc) und damit die AGENTS.md immer, die detaillierten docs/-Dateien dagegen nur bei Bedarf.

Bei Skills und MCP-Konfiguration funktioniert dieser Verweis-Trick nicht – hier müssen die Dateien tatsächlich an beiden Orten liegen. Naheliegend wären Symlinks, doch die verhalten sich zwischen Windows und Linux/macOS unterschiedlich und sorgen erfahrungsgemäß für Reibung. Deshalb kopieren wir die Dateien stattdessen mit einem kleinen Node-Skript. Es spiegelt .agents/skills/ nach .claude/skills/ und .cursor/mcp.json nach .mcp.json.
Damit niemand versehentlich die generierten Kopien bearbeitet, legt das Skript zusätzlich zwei DO_NOT_EDIT-Dateien an – eine im gespiegelten Skills-Ordner und eine für die MCP-Konfiguration. Sie weisen unmissverständlich darauf hin, dass Änderungen hier beim nächsten Sync überschrieben werden und stattdessen in der jeweiligen Quelle erfolgen müssen.
Damit das Skript zuverlässig läuft, hängen wir es an die üblichen Lebenszyklen: Es wird über das prepare-Skript von npm (also nach npm install) ausgeführt und zusätzlich über einen Pre-Commit-Hook angestoßen, sobald sich eine der Quellen geändert hat. So bleiben die Kopien automatisch aktuell, ohne dass jemand daran denken muss.
Und schließlich der Stop-Hook: Auch ihn versorgen wir aus einer Quelle. Jetzt, mit dem zweiten Werkzeug, zeigt sich, wofür wir die Indirektion eingeplant haben – denn jeder Coding-Agent hat eigene Konventionen, wie ein Stop-Hook mit ihm kommuniziert. Die Unterschiede betreffen vor allem zwei Dinge. Erstens den Exit-Code – also den Rückgabewert, mit dem ein Prozess sein Ergebnis an das aufrufende Werkzeug meldet (bei Betriebssystemprozessen spricht man von Exit-Code bzw. Exit-Status, nicht von „Result Code"). Claude Code etwa wertet einen Exit-Code von 2 als „blockieren und neu versuchen", während Cursor auch im Fehlerfall den Exit-Code 0 erwartet und anhand der Ausgabe entscheidet, wie es weitergeht. Zweitens die Nutzung von stdout und stderr: Cursor liest ein JSON-Objekt aus stdout und erwartet die Rückmeldung an das Modell in einem bestimmten Feld; Claude Code dagegen nimmt den Text aus stderr als Feedback für den Agenten. Manche Werkzeuge geben dem Hook über stdin zusätzlich Kontext mit – etwa, ob der Lauf abgebrochen wurde.
Genau diese Unterschiede fängt das jeweilige Hook-Skript ab: Der Prüfkern in ci-checks.mjs (und die kleine read-input.mjs) bleibt unverändert – für Claude Code ergänzen wir nur ein zweites, ebenso schlankes Hook-Skript (scripts/hooks/claude-stop-hook.mjs):
import process from 'node:process';
import { runChecks } from '../ci-checks.mjs';
const result = runChecks({ capture: true });
if (result.status === 'error') {
process.stderr.write(result.message);
process.exit(2);
}
process.exit(0);Hier schlägt Claudes Konvention durch: Statt eines JSON-Objekts auf stdout nutzt Claude Code den Exit-Code als Signal – 2 bedeutet „blockieren und den Text aus stderr als Feedback an den Agenten zurückspielen". Die wenigen Zeilen übersetzen das Ergebnis also lediglich in Claudes Erwartungen; der gesamte Prüfkern bleibt geteilt.
Registriert wird der Hook bei Claude Code nicht über eine eigene Hook-Datei, sondern in der .claude/settings.json:
{
"hooks": {
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "node scripts/hooks/claude-stop-hook.mjs",
"timeout": 600
}
]
}
]
}
}So teilen sich Cursor AI und Claude Code denselben Prüfkern und unterscheiden sich nur in wenigen Zeilen ihres jeweiligen Hook-Skripts.
Ausbau auf GPT, Codex CLI, Google Antigravity und Co.
Viele aktuelle Coding-Agents und Agent-Tools orientieren sich inzwischen an ähnlichen Konventionen: Eine AGENTS.md beschreibt projektweite Instruktionen, Skills liegen häufig in einem eigenen Skills-Verzeichnis, und MCP-Server werden über tool-spezifische Konfigurationsdateien registriert. Die Details unterscheiden sich jedoch von Werkzeug zu Werkzeug – etwa bei Hooks, lokalen Instruktionsdateien oder der MCP-Konfiguration. Beispielsweise erwartet Codex die MCP-Konfiguration in einer TOML-Datei (etwa .codex/config.toml), während Antigravity ein JSON-Format (etwa mcp_config.json) nutzt.
Deshalb behandeln wir AGENTS.md, .agents/skills/ und unsere MCP-Basiskonfiguration als zentrale Quellen und lassen ein kleines Sync-Skript daraus die benötigten Zielformate erzeugen. Kommt ein weiteres Tool hinzu, muss meistens nur dieses Skript erweitert werden. Da das Skript bewusst schlicht gehalten ist, eignet sich genau diese Anpassung hervorragend für AI-assisted Coding: Der Agent kann die Dokumentation des neuen Werkzeugs nachschlagen, das benötigte Zielformat ableiten und das Sync-Skript entsprechend erweitern.
Für genau diese Aufgabe gibt es inzwischen auch fertige Werkzeuge wie rulesync oder ruler. Sie pflegen Rules, Skills, MCP-Server – teils sogar Hooks – aus einer zentralen Konfiguration und verteilen sie an die jeweiligen Coding-Agents. Wir haben uns hier dennoch bewusst für die leichtgewichtige Eigenlösung entschieden: So bleiben die De-facto-Standards AGENTS.md und .agents/skills/ unsere unmittelbare Quelle der Wahrheit, statt das Setup an das jeweils eigene Quellformat eines solchen Tools zu binden (etwa ein zentrales .rulesync/-Verzeichnis). Wer ohnehin viele Agents und Artefakttypen zu synchronisieren hat, für den können diese Tools die bessere Wahl sein – für unser überschaubares Setup wiegt der Vorteil, direkt auf den etablierten Standard-Dateien zu arbeiten, schwerer.
Dasselbe Prinzip greift bei den Stop-Hooks. Weil die eigentliche Prüflogik in ci-checks.mjs (und die kleine read-input.mjs) werkzeugneutral ist, kostet ein weiteres Tool meist nur ein neues, wenige Zeilen langes Hook-Skript, das dessen Konventionen für Exit-Code und stdout/stderr bedient – plus dessen Registrierung am erwarteten Ort. Auch das ist eine ideale Aufgabe für AI-assisted Coding: Der Agent liest die Hook-Dokumentation des neuen Werkzeugs nach und leitet das passende Hook-Skript daraus ab.
Genau hier spielen Sprachmodelle ihre Stärke aus: Sie sind ausgesprochen gut darin, unser bestehendes Setup an die aktuellen Konventionen weiterer Coding-Agents anzupassen. Man kann den Agenten schlicht bitten, die Dokumentation des neuen Werkzeugs heranzuziehen, das passende Zielformat abzuleiten und das Sync-Skript entsprechend zu erweitern – die Anbindung eines weiteren Tools wird damit selbst zu einer Aufgabe für AI-assisted Coding.
AI-assisted Coding in Aktion: ein neues Feature generieren
Genug Theorie – sehen wir das Setup in Aktion. Wir fordern im Coding Agent an, dass wir künftig auch Airports verwalten wollen. Zur Vereinfachung werden diese direkt im Speicher gehalten, in einem Datenzugriffsservice namens AirportClient. Außerdem wollen wir beim Warten von Flügen die Airports aus Dropdown-Feldern auswählen können.
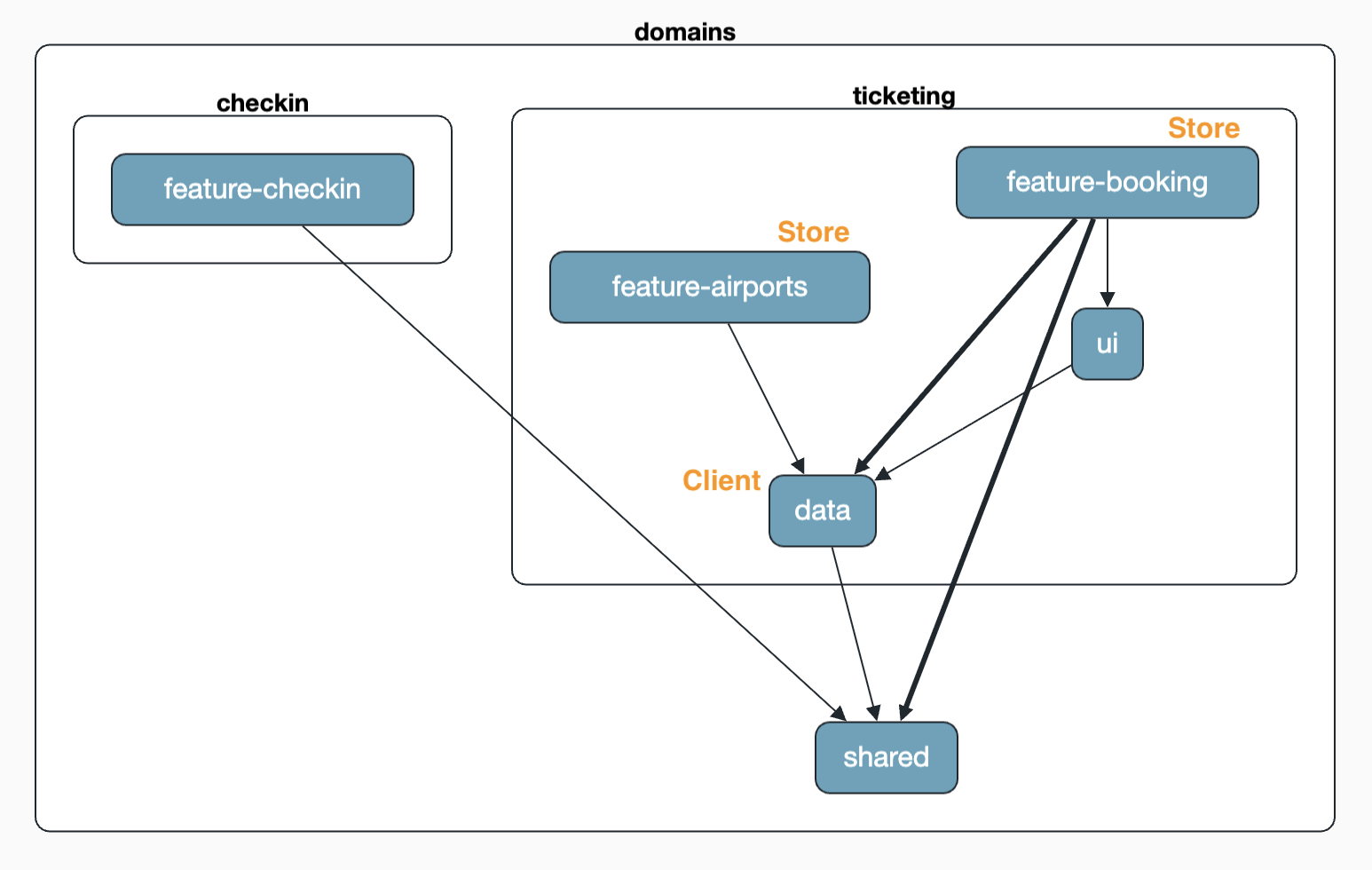
Das Ergebnis kann sich sehen lassen. Die beiden Features airports und booking bekommen jeweils einen eigenen Store – und das ist genau richtig, denn die Features haben unterschiedlichen Zustand. Ein Filter im einen Feature soll sich nicht auf das andere auswirken. (Wäre das doch erwünscht, müssten wir das in der architecture-boundaries.md nachziehen.) Beide Stores nutzen aber denselben AirportClient im Data-Layer.
Würde der Agent dabei gegen eine Linting-Regel wie eine Sheriff-basierte Architekturvorgabe verstoßen – oder schlügen Tests oder Build fehl –, ginge die IDE dank des Stop-Hooks automatisch in eine neue Runde, bis die Checks grün sind.
Spannend wird es, wenn wir die Anforderungen variieren. Geben wir explizit an, in beiden Features denselben Store haben zu wollen, verschiebt der Coding-Agent den Store von selbst in den Data-Layer – exakt so, wie wir es in der architecture-boundaries.md beschrieben haben. Damit löst er nebenbei eine der zentralen Herausforderungen von Feature Slicing: das Refactoring, also das Verschieben von lokalem Code in globalere Bereiche, sobald es tatsächlich nötig wird.
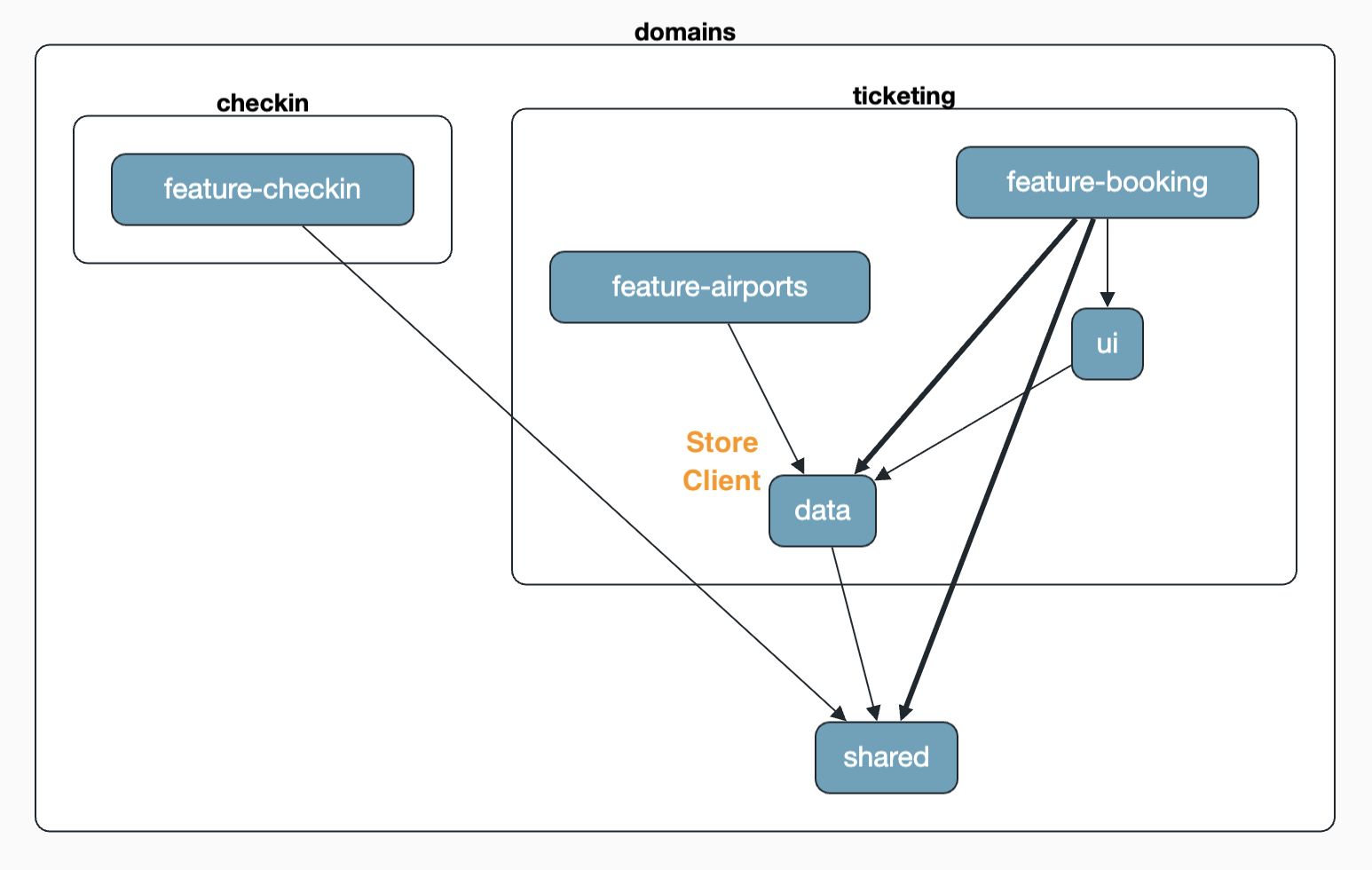
Solange wir uns innerhalb derselben Domäne bewegen, darf der Agent den Code nach den dokumentierten Regeln refactoren – etwa das zuvor gezeigte Verschieben des Stores in den Data-Layer. Noch interessanter wird es, wenn wir den AirportClient auch in der checkin-Domäne wiederverwenden wollen. Damit sind Domänengrenzen betroffen, und genau dann muss der Agent nachfragen. Jetzt konfrontiert uns der Agent mit einer Frage – und das ist gewollt. In der architecture-boundaries.md haben wir festgelegt, dass in genau diesem Fall Rücksprache zu halten ist, weil ein domänenübergreifender Zugriff eine bewusste Architekturentscheidung ist. Mögliche Optionen sind dann etwa: den Code nach shared verschieben, ihn über eine öffentliche API der ticketing-Domäne veröffentlichen oder die Anforderung anders zuschneiden.
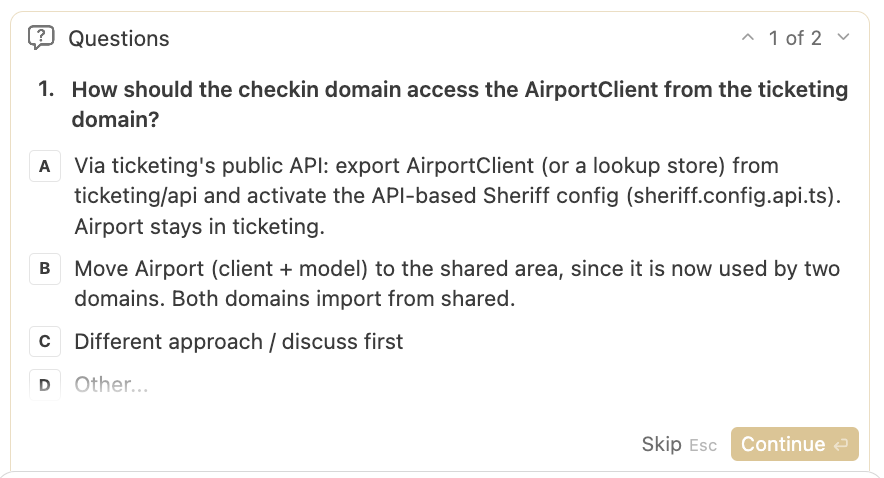
Entscheiden wir uns dafür, den AirportClient in den Shared-Bereich zu verschieben, sieht das Ergebnis wie oben aus: Beide Domänen greifen nun auf den gemeinsamen Code in shared zu.
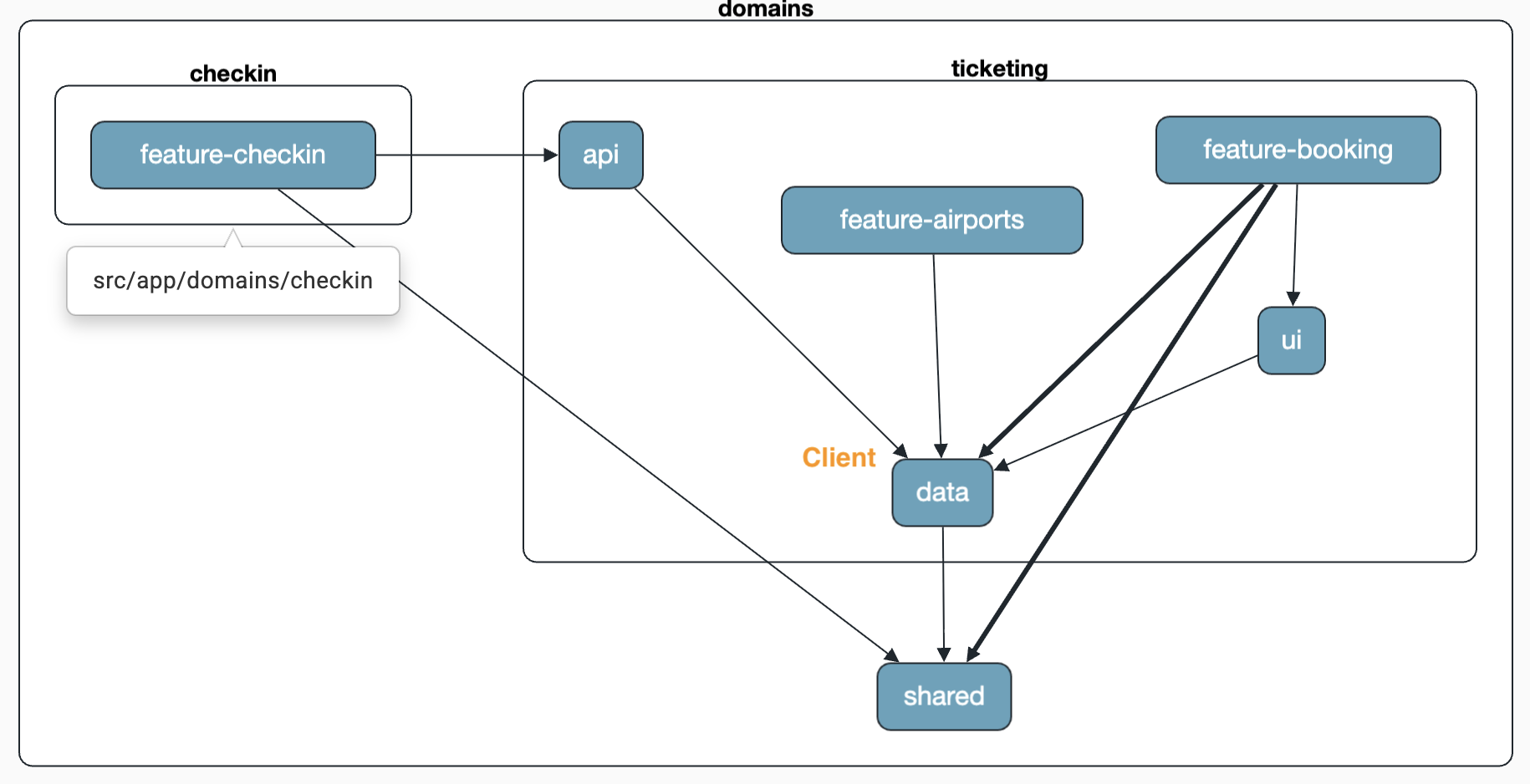
Wählen wir stattdessen den API-Weg, bleibt der AirportClient in der ticketing-Domäne und wird über eine api/index.ts veröffentlicht. Der Agent passt dazu die Sheriff-Konfiguration so an, dass domain:checkin Zugriff auf domain:ticketing/api erhält – aber eben nur auf die dort ausgewählten, freigegebenen Elemente:
Rules und Skills iterativ verfeinern
Eine ehrliche Einordnung gehört dazu: Das Erstellen guter Rules und Skills ist kein einmaliger Akt, sondern ein iterativer Prozess. Tut der Agent etwas, das man nicht möchte, sind diese Dateien nachzuschärfen und zu konkretisieren. Auch dabei helfen Sprachmodelle und Coding-Agents übrigens hervorragend – man kann sie schlicht bitten, aus einem unerwünschten Verhalten eine präzisere Regel zu formulieren.
Erfahrungsgemäß hängt es zudem stark vom verwendeten Modell ab, wie streng und explizit man formulieren muss. Manche Modelle folgen schon knappen Hinweisen, andere brauchen unmissverständliche, fast schon penible Vorgaben. Es lohnt sich, das Regelwerk auf das tatsächlich eingesetzte Modell hin zu kalibrieren.
Gespeicherte Prompts und Plan-Modus
Aus der Praxis noch zwei Empfehlungen, die den Unterschied zwischen Frust und Flow ausmachen können. Erstens habe ich gute Erfahrungen mit gespeicherten Prompts gemacht, die ich bei Bedarf in den Chat ziehe. Das hilft enorm beim iterativen Verfeinern und vor allem bei analogen Folgeaufgaben.
Zweitens lasse ich den Agenten gerne zuerst explizit planen – über den Plan-Modus, den viele IDEs inzwischen anbieten – und gebe den Plan erst dann zur Umsetzung frei. So lassen sich Missverständnisse ausräumen, bevor auch nur eine Zeile Code geschrieben wird.
Eigene Skills: Architektur-Review ausführen
Verfeinerte Prompts lassen sich auch zu eigenen Skills ausbauen. Dabei sind wir nicht auf das Generieren von Code beschränkt – wir können sie auch für wiederkehrende Aufgaben wie ein Architektur-Review nutzen. Unser eigener Skill dafür liegt unter .agents/skills/architecture-review/SKILL.md und ist bewusst kompakt:
---
name: architecture-review
description: Review Angular code against the repository architecture rules in docs/architecture-boundaries.md, including Sheriff boundaries, layering, feature slicing, shared code, and state management conventions.
---
# Review Angular Architecture
Use this skill when reviewing Angular code for architectural quality.
Before reviewing, read:
- `docs/architecture-boundaries.md`
- `AGENTS.md` if present
- `docs/architecture-state-management.md` if state management is involved
- the relevant Sheriff configuration
- the changed files and their imports
Treat `docs/architecture-boundaries.md` as the source of truth.
...Der Skill macht die docs/architecture-boundaries.md zur maßgeblichen Quelle, gibt einen klaren Review-Prozess vor und beschreibt das gewünschte Ausgabeformat – von der Zusammenfassung über Findings nach Schweregrad bis zum konkreten Fix. Damit wird aus einem schwammigen „Schau mal drüber" ein reproduzierbares Review.
Gestartet wird das Review mit einem einfachen Prompt:
Perform an architecture review for the new airport-related features (skill architecture-review).Den Namen des Skills muss man nicht zwingend angeben. Wer aber ganz sichergehen will, dass der Coding-Agent genau diesen Skill heranzieht, kann ihn explizit nennen.
Mehr Kontext: ADRs und MCP-Server für Confluence und Co.
Architekturentscheidungen haben fast immer eine Geschichte: Warum relaxed Layering? Warum Feature-Slicing? Diese Begründungen halten Teams in Architecture Decision Records (ADRs) fest. Im Branch ai-arc-adr binden wir solche ADRs ein – etwa rund um relaxed Layering, Domänen, Feature-Slicing und State Management.
Dabei gilt es, den Kontext des Agenten nicht unnötig vollzustopfen. Würden wir sämtliche ADRs permanent mitliefern, ginge das auf Kosten von Übersicht und Tokenbudget. Deshalb leiten wir aus den ADRs knappe Regeln ab – auch das gelingt mit Sprachmodellen gut – und verlinken von diesen Regeln zurück auf die ausführlichen ADRs, damit der Coding-Agent bei Bedarf nachschlagen kann. In der docs/architecture-boundaries.md sieht das etwa so aus:
## Shared Code
_(derived from [ADR-0004](adr/0004-feature-slicing-and-shared-code.md))_
- Promote code to a shared area only when at least two independent features require it.
- Avoid premature shared abstractions.
## State Management
_(derived from [ADR-0003](adr/0003-ngrx-signal-store-for-state.md))_
- Follow `docs/architecture-state-management.md` where applicable.Die Regel steht also kompakt im Kontext, die Begründung bleibt einen Klick entfernt. Das hält den Prompt schlank und macht Entscheidungen trotzdem nachvollziehbar.
Über ADRs im Repository hinaus lohnt ein Blick auf die Werkzeuglandschaft: Plattformen wie Confluence bieten inzwischen ebenfalls MCP-Server an. Damit kann der Agent bei Bedarf direkt auf dort dokumentierte Entscheidungen und Vorgaben zugreifen – ohne dass wir sie ins Repository kopieren müssen.
Fazit
Solide Architekturen entstehen beim AI-assisted Coding nicht von selbst – sie sind das Ergebnis bewusst bereitgestellten Kontexts. Dabei lohnt es sich, die Rollen klar zu trennen:
Rules sagen, welche Projektregeln sichtbar sein müssen. Skills beschreiben, wie bei einer bestimmten Aufgabe gearbeitet wird. MCP liefert Zugriff auf externe Werkzeuge und Wissensquellen.
Und wir müssen uns auf die unterschiedlichen Dateikonventionen verschiedener Agenten einstellen. Um dennoch eine Quelle der Wahrheit zu behalten, nutzen wir Verweise und kleine Skripte, die Dateien kopieren.
Mindestens ebenso wichtig ist die Feedback-Loop: Ein Hook, der deterministische Werkzeuge wie Sheriff, Tests und Build ausführt, gibt dem Agenten ein verlässliches, maschinelles Korrektiv – und verwandelt einen Architekturverstoß in eine automatische Korrekturrunde statt in technische Schuld.
In unserem Beispiel hat sich eine vertikale Architektur mit Domänen und Feature Slicing bewährt. Selbst die klassische Herausforderung von Feature Slicing – das spätere Verschieben von lokalem Code in globalere Bereiche – ließ sich elegant lösen, weil der Agent dieses Refactoring auf Basis klarer Regeln selbst übernimmt und bei heiklen Entscheidungen Rücksprache hält.
Und schließlich: Es bleibt ein iterativer Prozess. Rules und Skills wachsen mit den Erfahrungen, die man mit dem jeweiligen Modell macht. Wer bereit ist, diese Leitplanken kontinuierlich zu schärfen, bekommt das Beste aus beiden Welten – die Geschwindigkeit der AI und die Verlässlichkeit einer durchdachten Architektur.
Mehr dazu: Angular Architecture Workshop: AI & Signals (Remote, Interaktiv, Advanced)
Wir haben unseren Workshop rundum erneuert und legen jetzt einen besonderen Fokus auf AI-assisted Architecture und Signals. Werde zum Experten für unternehmensweite und langlebige Angular-Anwendungen und lerne, AI für wartbare Architekturen einzusetzen.

Deutsche Version | English Version
FAQ
Warum reicht es nicht, dem Coding-Agent die Architektur einmal zu erklären?
Ein Sprachmodell optimiert standardmäßig auf funktionierenden Code, nicht auf die Einhaltung Ihrer Zielarchitektur. Ohne explizite, dauerhaft verfügbare Vorgaben (Rules) und eine deterministische Feedback-Loop (Hook mit Sheriff, Tests, Build) weicht die Struktur über die Zeit auf.
Wie kommt das Architektur-Feedback zum Modell zurück?
Über einen Stop-Hook führt die IDE ein Node-Skript aus, das Linter (inklusive Sheriff), Tests und Build startet. Schlägt etwas fehl, geht der Agent automatisch in eine neue Runde und korrigiert seinen Code anhand der konkreten Fehlermeldung.
Wie unterstützt man mehrere Werkzeuge wie Cursor AI und Claude Code gleichzeitig?
Rules werden über Verweise gebündelt (z. B. zeigt CLAUDE.md auf AGENTS.md), sodass es eine Quelle der Wahrheit gibt. Skills und MCP-Konfiguration werden per Node-Skript an die jeweils erwarteten Orte kopiert – bewusst statt per Symlink, da sich Symlinks zwischen Betriebssystemen unterschiedlich verhalten.
Was ist der Unterschied zwischen Rules, Skills und MCP-Servern?
Rules sagen, welche Projektregeln sichtbar sein müssen – kurze rote Linien dauerhaft, detaillierte Regeln bei passender Aufgabe. Skills bündeln aufgabenspezifisches Wissen und konkrete Arbeitsabläufe und beschreiben, wie ein Agent bei bestimmten Aufgaben vorgeht; je nach Tool werden sie automatisch oder explizit aktiviert. MCP-Server geben dem Agenten Zugriff auf externe Werkzeuge und Wissensquellen, etwa die Angular-Dokumentation oder dokumentierte Entscheidungen in Confluence.
Wie passen ADRs ins Bild, ohne den Kontext zu überladen?
Aus den ADRs werden knappe Regeln abgeleitet, die im Kontext stehen; auf die ausführlichen ADRs wird lediglich verlinkt. So bleibt der Prompt schlank, und der Agent kann die Begründung bei Bedarf nachschlagen.
