

Rund 40 Sekunden. Über 46.000 Tokens. Für ein einziges Dashboard. So sah die erste Version meiner A2UI-Lösung aus – und so etwas will niemand in Produktion sehen, weder die Anwenderinnen und Anwender, die auf eine leere Oberfläche starren, noch die Person, die am Monatsende die Rechnung des Modellanbieters bezahlt.
Heute liegt dieselbe Lösung bei rund 0,1 Sekunden und etwas über 1.500 Tokens. Das ist eine Beschleunigung um den Faktor 300 und eine Reduktion des Tokenverbrauchs um den Faktor 30. Der eigentlich spannende Teil daran ist aber nicht die Zahl, sondern der überraschend einfache Hebel dahinter – und die Lektion, die sich daraus für jede LLM-gestützte UI-Generierung ableiten lässt.
In einem letzten Artikel habe ich gezeigt, wie sich mit A2UI ganze Dashboards generativ erzeugen lassen. Das Ergebnis sah so aus:
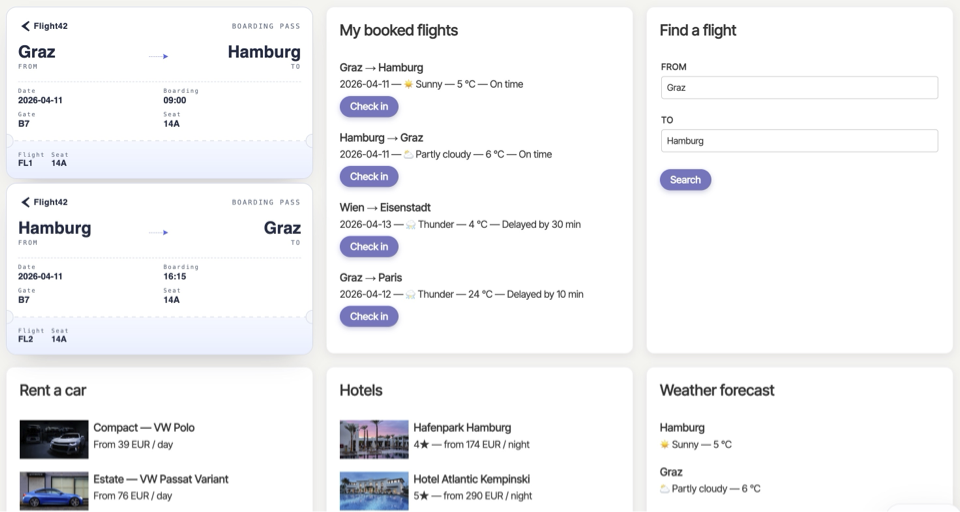
In diesem Artikel zeige ich, wie ich genau diese Lösung dramatisch beschleunigt habe – und welche Konsequenzen diese Optimierung mit sich bringt. Denn jeder Performancegewinn hat seinen Preis.
Das Problem: Warum die A2UI-Generierung langsam und teuer war
Kurz zur Einordnung: A2UI ist ein Protokoll, mit dem sich Benutzeroberflächen – hier ein Dashboard – so beschreiben lassen, dass ein LLM sie generieren kann. Das Modell erzeugt also kein fertiges HTML, sondern eine strukturierte Beschreibung der Oberfläche, die der Client anschließend rendert. Genau dieses Generieren war in der ersten Version das Nadelöhr.
Um A2UI zu generieren, braucht man zunächst einen entsprechend langen Prompt mit guten Beispielen – klassisches One-Shot- bzw. Few-Shot-Prompting. Da LLMs ausgezeichnet mit solchen Beispielen umgehen können, habe ich nicht einmal die vollständige Spezifikation oder das JSON-Schema von A2UI in den Prompt kopiert. Trotzdem war das Ganze sehr umfangreich: Beim eingangs gezeigten Beispiel landeten wir bei über 43.000 Input-Tokens.
Dazu kommt: Das Generieren des A2UI-Markups anhand dieser Beschreibung dauerte entsprechend lange. Das Modell muss Token für Token eine umfangreiche Struktur produzieren – und genau das ist teuer.
Daneben muss das Modell immer wieder Function Calls absetzen, um die Daten für die einzelnen Kacheln zu ermitteln. Jeder dieser Aufrufe kostet zusätzliches Reasoning und damit Zeit und Tokens.
Und schließlich das vielleicht unangenehmste Problem: Beim Generieren von A2UI kann das Modell durcheinanderkommen und fehlerhaftes Markup erzeugen. Das Grunddesign von A2UI – das etwa tiefe Verschachtelungen bewusst vermeidet – hilft LLMs zwar spürbar. Aber Fehler lassen sich nicht völlig ausschließen, und jeder Fehler erzwingt weitere Korrekturschleifen. Besonders schwächere (und damit günstigere) Modelle sind davon betroffen.
So sah ein vollständiger Durchlauf in der ursprünglichen Variante aus:

Gut zu erkennen: Das Modell sammelt zunächst über mehrere Tool-Calls die Daten und generiert anschließend in einem einzigen, über 30 Sekunden langen Schritt das vollständige A2UI-Markup. Dieser eine Schritt dominiert die gesamte Laufzeit.
Die Lösung: eine anwendungsspezifische DSL statt A2UI-Markup
Die Idee ist denkbar einfach: eine kleine, anwendungsspezifische DSL (Domain-Specific Language) – also eine bewusst minimal gehaltene, auf genau einen Zweck zugeschnittene Beschreibungssprache –, mit der sich genau das beschreiben lässt, was generiert werden soll – ein Dashboard mit bestimmten, zur Anwendung passenden Inhalten. In unserem Fall sieht diese DSL so aus:
{
"toolName": "renderDashboard",
"toolCallId": "call_2mO2fjJD4ZpGHna4yXsW8QG0",
"toolInput": {
"tiles": [
{
"type": "boardingPasses",
"count": 2
},
{
"type": "bookedFlightsList",
"showCheckInButton": true
},
{
"type": "flightSearch",
"defaultFrom": "Graz",
"defaultTo": "Hamburg"
},
{
"type": "rentalCars"
},
{
"type": "hotels"
},
{
"type": "weatherList"
}
]
}
}Das Modell wird damit nur noch angewiesen, die Anforderung der Benutzerin oder des Benutzers in diese DSL zu übersetzen. Mehr macht es nicht. Da das zu einem sehr kurzen Ergebnis führt, ist die Umwandlung schnell, weniger fehleranfällig, und auch schwächere Modelle kommen problemlos damit klar.
Es gibt noch einen weiteren, oft unterschätzten Vorteil: Die Anwendung wird damit stärker in einen definierten Rahmen gezwungen. Das Modell kann keine Dinge mehr tun, die das Anwendungsdesign nicht vorgesehen hat. Das Ergebnis wird so – trotz des grundsätzlich nicht-deterministischen Verhaltens eines LLMs – deutlich kontrollierbarer.
Diese DSL wird anschließend für zwei Zwecke verwendet:
- Umwandlung in A2UI – deterministisch, im Code, ganz ohne Modell.
- Abrufen der nötigen Daten – ebenfalls ohne weiteres Reasoning des Modells.
Der entscheidende Punkt: Sowohl die Übersetzung in A2UI als auch das Beschaffen der Daten passieren jetzt in gewöhnlichem Anwendungscode. Das Modell ist daran nicht mehr beteiligt.
Und der Client merkt von all dem nichts. Er bekommt nach wie vor A2UI geliefert und muss daher keine Details der Anwendungslogik kennen. Die DSL ist eine reine Implementierungsentscheidung auf der Serverseite.
Konsequenzen: Vor- und Nachteile des DSL-Ansatzes
Wie immer in der Softwarearchitektur gibt es kein „kostenlos". Halten wir die Vor- und Nachteile fest.
Pro:
- Deutlich performanter.
- Deutlich weniger Tokenverbrauch – und damit deutlich geringere Kosten.
- Verhalten wird kontrollierbarer.
- Einfacher für schwächere (günstigere) Modelle.
- Der Client muss nicht vorab alle möglichen Darstellungsoptionen kennen.
Contra:
Das kontrollierbare Verhalten ist zugleich der zentrale Nachteil: Die Dynamik beschränkt sich auf jene Aspekte, die die DSL ausdrücklich vorsieht. Will man etwa die Menge der ausgegebenen Daten begrenzen (z. B. maximal drei Hotels), Wetterinfos ergänzen oder den Button zum Einchecken weglassen, muss die DSL dafür explizit Möglichkeiten bereitstellen. Was sie nicht vorsieht, ist schlicht nicht möglich. Unsere Beispiel-DSL kann etwa nicht ausdrücken, welche Informationen eines Flugs präsentiert werden sollen oder ob diese tabellarisch oder als Liste darzustellen sind.
Man tauscht also einen Teil der generativen Flexibilität gegen Geschwindigkeit, Kosten und Kontrolle ein. Für die allermeisten Geschäftsanwendungen ist das ein hervorragender Tausch – denn dort sind Vorhersehbarkeit und Performance fast immer wichtiger als grenzenlose Freiheit bei der Darstellung.
Neu: Agentic UI with Angular
Wenn du solche Performance- und Architekturentscheidungen rund um A2UI nicht nur punktuell, sondern sauber in größere Angular-Anwendungen einbetten willst: In meinem Buch Agentic UI mit Angular gehe ich genau auf diese Patterns und Trade-offs – inklusive DSLs, Caching und offener Standards wie AG-UI, A2UI und MCP – im Detail ein.

Noch mehr Performance: Caching
Solange die Beschreibung gleich bleibt, kann auch das generierte Markup gleich bleiben. In der Regel ist das sogar erwünscht: Eine erneute Interpretation, die zu geringfügigen Abweichungen führt, wäre für die Anwenderinnen und Anwender eher verwirrend. Nur die Daten müssen bei jedem Aufruf neu abgerufen werden.
Hier spielt uns ein grundlegendes Feature von A2UI in die Karten: Man kann Struktur und Daten trennen. Über eine updateComponents-Nachricht lässt sich die gewünschte Struktur bekanntgeben:
{
"version": "v0.9",
"updateComponents": {
"surfaceId": "dash-bf0140eb-f2e4-4c53-a74b-56e9445cc7dc",
"components": [
[...],
{
"id": "t0-t0",
"component": "TicketWidget",
"ticketId": {
"path": "/t0/tickets/0/ticketId"
},
"from": {
"path": "/t0/tickets/0/from"
},
"to": {
"path": "/t0/tickets/0/to"
},
"date": {
"path": "/t0/tickets/0/date"
},
"delay": {
"path": "/t0/tickets/0/delay"
}
},
[...]
]
}
}Darin können sich Datenbindungsausdrücke befinden, die auf ein Datenmodell verweisen. Im gezeigten Beispiel zeigt die Eigenschaft path auf ein Array /t0/tickets, dessen Einträge Eigenschaften wie ticketId, from, to etc. aufweisen.
Diese Daten lassen sich anschließend mit eigenen Nachrichten an den Client senden:
{
"version": "v0.9",
"updateDataModel": {
"surfaceId": "dash-bf0140eb-f2e4-4c53-a74b-56e9445cc7dc",
"path": "/t0",
"value": {
"tickets": [
{
"ticketId": 1,
"from": "Graz",
"to": "Hamburg",
"date": "2026-06-06",
"delay": 0
},
{
"ticketId": 2,
"from": "Hamburg",
"to": "Graz",
"date": "2026-06-06",
"delay": 0
}
]
}
}
}Diese Trennung ist die Grundlage für unser Caching: Die Struktur ist bei gleicher Beschreibung deterministisch reproduzierbar; neu ermittelt werden müssen vor allem die Daten, die per updateDataModel übertragen werden. In unserer Implementierung cachen wir dazu die kompakte DSL. Aus ihr entsteht die gesamte – und in der Regel verhältnismäßig umfangreiche – updateComponents-Nachricht bei Folgeaufrufen deterministisch im Anwendungscode; das Modell wird dafür nicht mehr benötigt.
In unserer Implementierung dient ein Hash der vom Benutzer gelieferten textuellen Beschreibung als Schlüssel. In der Praxis wird das jeweilige Dashboard häufig in einem Design-Modus der Anwendung als Datensatz hinterlegt – und genau die ID dieses Datensatzes, der das Dashboard repräsentiert, ist dann der Cache-Key.
Das Resultat: 300-mal schneller, 30-mal weniger Tokens
Durch die DSL sind drastische Beschleunigungen möglich. Vergleichen wir noch einmal die beiden Welten direkt:
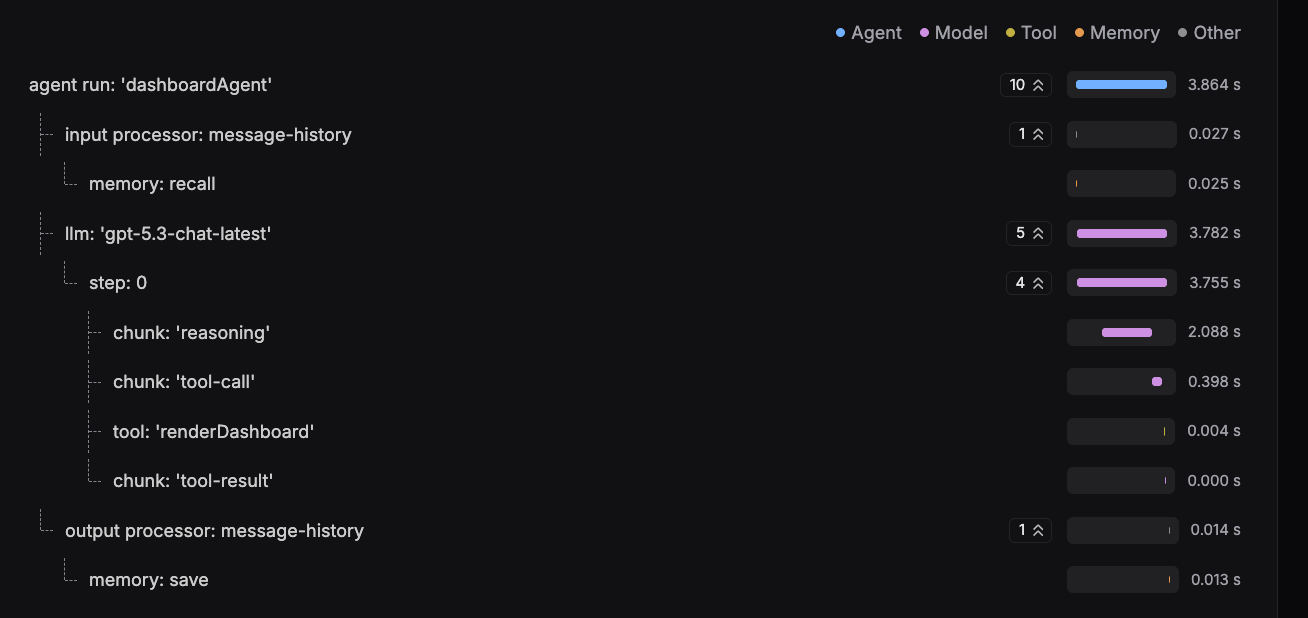
Das Modell erstellt nur noch die DSL aus der Anfrage – nicht mehr das vollständige A2UI-Markup. Daraus ergibt sich ein netter Seiteneffekt: Aus der DSL lassen sich auch die nötigen Tool-Calls für die Datenbeschaffung ableiten. Das Modell muss sich also nicht mehr selbst darum kümmern, was in zusätzlichen, kleineren Performanceverbesserungen resultiert – schlicht, weil weniger Reasoning für einzelne Tool-Calls anfällt.
Die zweite große Verbesserung liefert das Caching: Hier wird das Modell für identische Dashboards gar nicht mehr benötigt. Die DSL kommt direkt aus dem Cache; die mit A2UI beschriebene Struktur wird daraus deterministisch im Anwendungscode erzeugt, und lediglich die aktuellen Daten werden frisch geladen.
Und damit sind wir wieder bei den Zahlen vom Anfang: aus rund 40 Sekunden und über 46.000 Tokens wurden rund 0,1 Sekunden und etwas über 1.500 Tokens – Faktor 300 bei der Geschwindigkeit, Faktor 30 bei den Tokens. Wichtig: Die Token-Reduktion um den Faktor 30 ergibt sich bereits allein aus der DSL, denn das Modell muss nur noch diese kompakte Beschreibung statt des vollständigen A2UI-Markups erzeugen. Das Caching setzt obendrauf: Bei einem Cache-Treffer wird das Modell gar nicht mehr aufgerufen – es fallen also überhaupt keine Tokens mehr an.
Fazit: LLM für die Intention, Code für die Struktur
Der Lösungsweg ist im Kern eine bewusste Verschiebung von Verantwortung: Statt das LLM umfangreiches A2UI-Markup generieren zu lassen, übersetzt es die Anfrage nur noch in eine kompakte, anwendungsspezifische DSL. Die teure Arbeit – das Erzeugen der Struktur und das Beschaffen der Daten – erledigt anschließend deterministischer Anwendungscode.
Das Ergebnis spricht für sich: 300-mal schneller, 30-mal weniger Tokens und ein deutlich kontrollierbareres Verhalten, von dem gerade schwächere und günstigere Modelle profitieren. Mit Caching lässt sich das Modell für wiederkehrende Dashboards sogar vollständig aus dem heißen Pfad nehmen.
Der Preis dafür ist ein Stück generativer Freiheit: Die Anwendung kann nur noch das darstellen, was die DSL vorsieht. Für die meisten realen Geschäftsanwendungen ist das jedoch kein Verlust, sondern ein Gewinn – denn dort zählt Vorhersehbarkeit mehr als unbegrenzte Dynamik. Die übergeordnete Lehre lautet: Lassen Sie das LLM das tun, was es am besten kann – Intention verstehen –, und überlassen Sie das Erzeugen verlässlicher Strukturen Ihrem Code.
Interesse an produktionsreifen Agentic-UI-Architekturen?
In meinem Workshop beschäftigen wir uns mit AG-UI, A2UI, MCP Apps, HITL-Patterns und modernen Angular-Architekturen für reale agentische Systeme.

FAQ
Warum ist die direkte A2UI-Generierung mit einem LLM langsam und teuer?
Das Modell muss aus einem langen Few-Shot-Prompt (im Beispiel über 43.000 Input-Tokens) Token für Token eine umfangreiche Struktur erzeugen und nebenbei mehrere Tool-Calls für die Daten absetzen. Dieser eine Generierungsschritt dominiert die Laufzeit und kann zusätzlich fehlerhaftes Markup produzieren, das Korrekturschleifen erzwingt.
Wie beschleunigt eine anwendungsspezifische DSL die Generierung?
Das LLM übersetzt die Anfrage nur noch in eine kompakte DSL statt in vollständiges A2UI-Markup. Das Ergebnis ist kurz, schnell und weniger fehleranfällig. Die teure Arbeit – Umwandlung in A2UI und Datenbeschaffung – erledigt anschließend deterministischer Anwendungscode ganz ohne Modell.
Was bringt Caching zusätzlich?
A2UI erlaubt es, Struktur (updateComponents) und Daten (updateDataModel) zu trennen. In unserer Implementierung wird die kompakte DSL gecacht; die meist umfangreiche Struktur entsteht daraus deterministisch im Anwendungscode, und bei Folgeaufrufen müssen nur noch die kleinen Datennachrichten mit frischen Daten erzeugt werden. Für identische Dashboards wird das Modell dadurch gar nicht mehr benötigt.
Welchen Nachteil hat der DSL-Ansatz?
Die Dynamik beschränkt sich auf das, was die DSL ausdrücklich vorsieht. Was sie nicht abbildet, ist nicht möglich. Man tauscht also einen Teil der generativen Flexibilität gegen Geschwindigkeit, Kosten und Kontrolle – für die meisten Geschäftsanwendungen ein guter Tausch.
